Amazon Aurora のリストアにかかる時間
Amazon Aurora は、AWS の RDS のひとつとして提供されている RDB のサービスです。
MySQL および PostgreSQL の互換エディションが提供されています。
今回は、Aurora をスナップショットから復元する際の所要時間が、データサイズや DB インスタンスの種類によってどのように変化するのかを調べてみました。
検証条件
検証に使う Aurora は以下の構成としました。
- エディション : PorsgreSQL 13.5 互換
- キャパシティータイプ : Provisioned
- Aurora レプリカの作成 : なし
- リージョン : ap-northeast-1 (東京)
スナップショットからのリストア(復元)にかかる時間は、データサイズまたはインスタンスクラスによって違いが出るのではと考え、以下の組み合わせで全 9 パターンをリストアすることとしました。
- データサイズは 200GB / 400GB / 800GB の 3 パターン
- DB インスタンスクラスは t4g.medium, r6g.large, r6g.8xlarge の3パターン
インスタンスクラスは、以下の観点で選定しました。
- t4g.medium -> 選択可能な最も小さいもの
- r6g.large -> 現時点でデフォルトのインスタンスクラス
- r6g.8xlarge -> それなりの規模の商用環境などで使われる
計測にあたり、リストアにかかった時間の開始と終了は以下の定義としました。
RDS のイベントリストにはクラスタの作成開始が記録されないため、CloudTrail を利用しています。
- リストアの開始 : CloudTrail に記録された、当該 DB インスタンスの CreateDBInstance イベントのタイムスタンプ
- リストアの完了 : RDS のイベントに記録された、当該 DB インスタンスの "DB instance created" イベントのタイムスタンプ
検証データの作成
検証データの作成は こちら の stack overflow を参考にさせて頂きました。
1 テーブルあたり 13107200 行 (約 1,300 万行) のサンプルデータで、データサイズがほぼ 100 GB ぴったりになるため、きりの良い値で複数のデータサイズのスナップショットを用意することができました。
参考までに、下記の方のように pgbench でデータを投入し、CTAS でデータサイズをふくらませるという手段もありますね。
検証結果

最も所要時間が短かったのは 400GB x t4g.medium の 1,584 秒でした。
最も所要時間が長かったのは 800GB x r6g.8xlarge の 1,976 秒でした。
いずれの組み合わせも 1500 ~ 2000 秒の範囲に収まりました。
考察
検証結果から、200 ~ 800 GB程度のデータサイズでは、リストアの時間にデータサイズの大小がほぼ影響しないことがわかります。
追加で 1,200 GB x r6g.large も試しましたが、約 1,800 秒というところで他のパターンとの差はありませんでした。
また、インスタンスクラス毎の差はわずかにある(より大きいインスタンスクラスでリストアにより多くの時間を要している)ようにも見えますが、その差は大きくても 400 秒程度というところですので、実用上はこちらもほぼ差がないものと考えられます。
以上より、Aurora のリストアにかかる時間は、数百 GB 程度(おおよそ 1 TB 以下)のスナップショットであればインスタンスクラスに関わらず 30〜40 分程度で完了すると思っておいても良さそうです。
その他の気付き
参考までに、ひとつのスナップショットから複数のクラスタを一度にリストアしたところ、各クラスタの復元完了までの所要時間は上記検証の倍以上となりました。
おそらく、復元の際に行われるスナップショットからのデータ読み取りに関して I/O の制約があるものと思われます。
以下は Aurora MySQL 互換に関する AWS プレミアサポートのナレッジセンタに公開されている情報ですが、バックアップ作成時点でソース側に長時間実行されるトランザクションがある場合、リストアに通常よりも多くの時間を要することがあるようです。
商用の利用ではこうしたソースデータベース側の状態というのも影響要素になり得るかと思います。
あくまで個人による簡易な検証結果ですが、何かのお役に立てば幸いです。
GKE 1.22 with Node Local DNS Cache で Alpine 3.13+ の名前解決に失敗する
先日、GKE の静的リリースに 1.22 がやってきました。
今回は、Node Local DNS Cache を有効化した GKE 1.22 において、Alpine を使用する際に注意しておいたほうが良い挙動とその検証結果をご紹介します。
以下の検証は、現時点の GKE 1.22 における最新の静的リリースである 1.22.6-gke.1000 を用いて行っています。
Node Local DNS Cache の設定
GKE の Node Local DNS Cache には、アップストリームに基づいた CoreDNS ベースのイメージが使われており、一応 ”-gke.” のようなサフィックスが付いていますがほぼ同じような挙動となっています。
設定は GKE 独自のものがコントロールプレーンのバージョンに応じて自動的に展開される仕組みとなっています。
ちなみに、GKE の Node Local DNS Cache は CoreDNS をベースとしている一方、GKE クラスタのデフォルト DNS は kube-dns となっています(最近は Cloud DNS を利用する選択肢も出てきていますね)。
GKE の Node Local DNS Cache の設定は、"kube-system" Namespace の "node-local-dns" という ConfigMap の "Corefile" の値として定義されています。
GKE 1.22 では、以下のように AAAA クエリ (IPv6) に関する設定が追加されました。
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.3", GitCommit:"816c97ab8cff8a1c72eccca1026f7820e93e0d25", GitTreeState:"clean", BuildDate:"2022-01-25T21:25:17Z", GoVersion:"go1.17.6", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.6-gke.1000", GitCommit:"5595443086b60d8c5c62342fadc2d4fda9c793e8", GitTreeState:"clean", BuildDate:"2022-02-02T09:35:41Z", GoVersion:"go1.16.12b7", Compiler:"gc", Platform:"linux/amd64"}
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
event-exporter-gke-5877b595cd-6cw96 2/2 Running 0 7m
fluentbit-gke-lpvn6 2/2 Running 0 5m10s
fluentbit-gke-nsdwj 2/2 Running 0 5m9s
fluentbit-gke-z7l9p 2/2 Running 0 5m9s
gke-metrics-agent-bmb52 1/1 Running 0 5m10s
gke-metrics-agent-fq5gw 1/1 Running 0 5m9s
gke-metrics-agent-nrqvv 1/1 Running 0 5m9s
konnectivity-agent-7dbd649949-6vfcp 1/1 Running 0 5m2s
konnectivity-agent-7dbd649949-h864p 1/1 Running 0 5m2s
konnectivity-agent-7dbd649949-s7lx9 1/1 Running 0 6m50s
konnectivity-agent-autoscaler-698b6d8768-gq2dx 1/1 Running 0 6m46s
kube-dns-6bb46c7474-4vfqf 4/4 Running 0 7m14s
kube-dns-6bb46c7474-wlj7p 4/4 Running 0 5m1s
kube-dns-autoscaler-f4d55555-btzmw 1/1 Running 0 7m12s
kube-proxy-gke-cluster-1-22-clone-default-pool-058fd934-0pvn 1/1 Running 0 4m18s
kube-proxy-gke-cluster-1-22-clone-default-pool-058fd934-g67w 1/1 Running 0 4m38s
kube-proxy-gke-cluster-1-22-clone-default-pool-058fd934-nbrj 1/1 Running 0 4m20s
l7-default-backend-69fb9fd9f9-vsqf2 1/1 Running 0 6m42s
metrics-server-v0.4.5-bbb794dcc-87ttk 2/2 Running 0 4m44s
node-local-dns-8f2mf 1/1 Running 0 5m7s
node-local-dns-sf8l6 1/1 Running 0 5m7s
node-local-dns-t7v9x 1/1 Running 0 5m7s
pdcsi-node-tpxh6 2/2 Running 0 5m8s
pdcsi-node-wzgr8 2/2 Running 0 5m9s
pdcsi-node-z4r68 2/2 Running 0 5m10s
$ kubectl describe configmaps node-local-dns -n kube-system
Name: node-local-dns
Namespace: kube-system
Labels: addonmanager.kubernetes.io/mode=Reconcile
Annotations: app.kubernetes.io/created-by: kube-addon-manager
Data
====
Corefile:
----
cluster.local:53 {
errors
template ANY AAAA {
rcode NXDOMAIN
}
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.20.10 10.120.0.10
health 169.254.20.10:8080
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
expire 1s
}
prometheus :9253
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.120.0.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
expire 1s
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.120.0.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
expire 1s
}
prometheus :9253
}
.:53 {
errors
template ANY AAAA {
rcode NXDOMAIN
}
cache 30
reload
loop
bind 169.254.20.10 10.120.0.10
forward . __PILLAR__UPSTREAM__SERVERS__ {
force_tcp
}
prometheus :9253
}
BinaryData
====
Events: <none>
ひとつ前の GKE 1.21 (1.21.6-gke.1500) と比較してみるとわかりやすいかと思います。
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.3", GitCommit:"816c97ab8cff8a1c72eccca1026f7820e93e0d25", GitTreeState:"clean", BuildDate:"2022-01-25T21:25:17Z", GoVersion:"go1.17.6", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.6-gke.1500", GitCommit:"7ce0f9f1939dfc1aee910732e84cba03840df91e", GitTreeState:"clean", BuildDate:"2021-11-17T09:30:26Z", GoVersion:"go1.16.9b7", Compiler:"gc", Platform:"linux/amd64"}
WARNING: version difference between client (1.23) and server (1.21) exceeds the supported minor version skew of +/-1
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
event-exporter-gke-5479fd58c8-w889w 2/2 Running 0 5d6h
fluentbit-gke-8zj4h 2/2 Running 0 5d6h
fluentbit-gke-dwwjk 2/2 Running 0 5d6h
fluentbit-gke-h2wp2 2/2 Running 0 5d6h
gke-metrics-agent-72h26 1/1 Running 0 5d6h
gke-metrics-agent-dxsht 1/1 Running 0 5d6h
gke-metrics-agent-v27lf 1/1 Running 0 5d6h
konnectivity-agent-5b9bf44468-kttgm 1/1 Running 0 5d6h
konnectivity-agent-5b9bf44468-l74sx 1/1 Running 0 5d6h
konnectivity-agent-5b9bf44468-tmmzs 1/1 Running 0 5d6h
konnectivity-agent-autoscaler-5c49cb58bb-cdlk8 1/1 Running 0 5d6h
kube-dns-697dc8fc8b-8v5nl 4/4 Running 0 5d6h
kube-dns-697dc8fc8b-rzgcl 4/4 Running 0 5d6h
kube-dns-autoscaler-844c9d9448-v6gx2 1/1 Running 0 5d6h
kube-proxy-gke-cluster-1-21-default-pool-2a39355d-ghz4 1/1 Running 0 5d6h
kube-proxy-gke-cluster-1-21-default-pool-2a39355d-hw8r 1/1 Running 0 5d6h
kube-proxy-gke-cluster-1-21-default-pool-2a39355d-xl2n 1/1 Running 0 5d6h
l7-default-backend-69fb9fd9f9-wq98k 1/1 Running 0 5d6h
metrics-server-v0.4.4-857776bc9c-v5296 2/2 Running 0 5d6h
node-local-dns-j2r7v 1/1 Running 0 5d6h
node-local-dns-pzn75 1/1 Running 0 5d6h
node-local-dns-vcwr2 1/1 Running 0 5d6h
pdcsi-node-5d99x 2/2 Running 0 5d6h
pdcsi-node-g47xg 2/2 Running 0 5d6h
pdcsi-node-n6btn 2/2 Running 0 5d6h
$ kubectl describe configmaps node-local-dns -n kube-system
Name: node-local-dns
Namespace: kube-system
Labels: addonmanager.kubernetes.io/mode=Reconcile
Annotations: <none>
Data
====
Corefile:
----
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind 169.254.20.10 10.36.16.10
health 169.254.20.10:8080
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
expire 1s
}
prometheus :9253
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.36.16.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
expire 1s
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.36.16.10
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
expire 1s
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 10.36.16.10
forward . __PILLAR__UPSTREAM__SERVERS__ {
force_tcp
}
prometheus :9253
}
BinaryData
====
Events: <none>
設定追加の契機
上述のように GKE 1.22 の Node Local DNS Cache に設定が追加された背景には、アップストリームにおけるプラグインの追加が関係していると思われます。
GKE 1.21 と GKE 1.22 のそれぞれにおける Node Local DNS Cache のバージョンは以下のとおりです。
- GKE 1.21 : 1.21.1-gke.0
- GKE 1.22 : 1.21.4-gke.0
以下の URL から、実際に GitHub でこのバージョン間の差分を確認することができます。
ふたつのバージョンの差はパッチバージョンレベルのみとなっていますが、この差分に設定追加のきっかけと思われるコミットが含まれています。
たどってみると、差分に含まれる以下のコミットで Node Local DNS Cache に dns64 プラグインが追加されていることがわかります。
このアップストリームの変更をきっかけに、GKE 1.22 の Node Local DNS Cache に AAAA クエリ (IPv6) の設定が追加された可能性が考えられそうです。
CoreDNS の dns64 プラグインの説明はこちらにあります。
変更の影響
今回の変更が何をもたらすのでしょうか。
タイトルのとおりですが、 Node Local DNS Cache を有効化した GKE 1.22 において、Alpine 3.13+ のコンテナが名前解決に失敗するようになる という影響が生じます。
DNS クライアントの実装によっては、A + AAAA ペアクエリの一方で NXDOMAIN が返却された場合にクエリ全体を失敗とみなすことがあり、Alpine 3.13+ が名前解決に使用している musl libc 1.2 系はまさにこのような挙動を取ります。
Node Local DNS Cache を有効化した GKE 1.22 (1.22.6-gke.1000) における実際の挙動は次のようになります。
$ kubectl run alpine313 --image=alpine:3.13 --tty -i sh If you don't see a command prompt, try pressing enter. / # nslookup www.google.com Server: 10.120.0.10 Address: 10.120.0.10:53 ** server can't find www.google.com: NXDOMAIN Non-authoritative answer: Name: www.google.com Address: 142.250.148.99 Name: www.google.com Address: 142.250.148.103 Name: www.google.com Address: 142.250.148.106 Name: www.google.com Address: 142.250.148.147 Name: www.google.com Address: 142.250.148.104 Name: www.google.com Address: 142.250.148.105 / # wget www.google.com wget: bad address 'www.google.com' / #
nslookup の結果から、AAAA クエリに対して NXDOMAIN が返却されていることがわかります。
これは上述の Node Local DNS Cache に加えられた設定変更によるものです。
Node Local DNS Cache はこの設定により、AAAA クエリに対して無条件に NXDOMAIN を返却しています。
wget の結果から、名前解決が失敗し、"bad address" のエラーとなっていることがわかります。
詳細は後述しますが、このとき musl libc は A + AAAA ペアクエリの一方 (ここでは AAAA クエリ) で NXDOMAIN が返却されたことにより、もう一方 (A クエリ) が成功する状況であってもクエリ全体を失敗とみなし、名前解決に失敗しています。
ちなみに、GKE 1.21 (+ Node Local DNS Cache) 、または Node Local DNS Cache なしの GKE 1.22 であれば、Alpine 3.13+ のコンテナも名前解決に成功します。
以下に Node Local DNS Cache なしの GKE 1.22 の環境における実行結果を示します。
$ kubectl run alpine313 --image=alpine:3.13 --tty -i sh If you don't see a command prompt, try pressing enter. / # nslookup www.google.com Server: 10.93.0.10 Address: 10.93.0.10:53 Non-authoritative answer: Name: www.google.com Address: 173.194.197.104 Name: www.google.com Address: 173.194.197.147 Name: www.google.com Address: 173.194.197.106 Name: www.google.com Address: 173.194.197.99 Name: www.google.com Address: 173.194.197.103 Name: www.google.com Address: 173.194.197.105 Non-authoritative answer: Name: www.google.com Address: 2607:f8b0:4001:c5a::69 Name: www.google.com Address: 2607:f8b0:4001:c5a::67 Name: www.google.com Address: 2607:f8b0:4001:c5a::6a Name: www.google.com Address: 2607:f8b0:4001:c5a::63 / # wget www.google.com Connecting to www.google.com (173.194.192.104:80) saving to 'index.html' index.html 100% |**************************************************************************************************************************| 14119 0:00:00 ETA 'index.html' saved / #
NXDOMAIN
上述の挙動の差を生んでいる NXDOMAIN について少し掘り下げてみましょう。
NXDOMAIN の定義を詳細化している RFC 8020 によれば、NXDOMAIN は「その名前にいかなる型のレコードも存在しない」ことを意味します。
アドレスファミリが AF_UNSPEC の場合、名前解決のために A クエリと AAAA クエリで計 2 回のクエリが発行されることになりますが、どちらか 1 回目のクエリで NXDOMAIN によってその名前に対するレコードの非存在を確認できれば、クエリの試行回数を最適化することができます。
一方、「その名前に他の型のレコード、もしくはサブドメインが存在し得る」という場合には、NXDOMAIN ではなく NODATA を返却する必要があります(NODATA は疑似 RCODE であり、実際には NOERROR + 空の Answer セクションの返却となります)。
これは RFC 8020 の 3.1. Updates to RFC 1034 で定義されています。
This document clarifies possible ambiguities in [RFC1034] that did not clearly distinguish Empty Non-Terminal (ENT) names ([RFC7719]) from nonexistent names, and it refers to subsequent documents that do. ENTs are nodes in the DNS that do not have resource record sets associated with them but have descendant nodes that do. The correct response to ENTs is NODATA (i.e., a response code of NOERROR and an empty answer section). Additional clarifying language on these points is provided in Section 7.16 of [RFC2136] and in Sections 2.2.2 and 2.2.3 of [RFC4592].
musl libc の作者であり現在も主要メンテナである Rich Felker 氏の下記 Issue のコメントでも、この挙動とセマンティクスの対応関係が言及されています。
したがって、musl libc 1.2 系の「A + AAAA ペアクエリの一方が成功する (Answer セクションで有効な IP アドレスの回答が得られる) 状況であったとしても、もう一方で NXDOMAIN が返却された場合にクエリ全体を失敗とみなす挙動」は、特殊なものではなく、DNS のセマンティクスに沿った挙動であると言えそうです。
一方、他の DNS クライアントでは、ペアクエリの一方で NXDOMAIN が返却されたとしても、もう一方のクエリで有効な IP アドレスが得られればこれを名前解決の結果とする実装もあるようです。
ライブラリによって異なる名前解決の挙動
Alpine は、軽量な Linux ディストリビューションとして GKE などのコンテナ実行環境でよく使われています。
しかし、Alpine の元々の用途は組み込み系であり、BusyBox と musl libc をベースとしているため、他の Linux ディストリビューションの多くが採用している glibc などとは実装が異なります。
musl libc, glibc はそれぞれのライブラリにネットワークの共通的な機能を備えており、どちらのライブラリを採用しているかで名前解決の際の挙動が変わってくるということになります。
musl libc, glibc のいずれでも構成可能な、Gentoo Linux を使って動作を確認してみます。
まずは Gentoo (5.10.90+) + musl libc 1.2.2 (musl-1.2.2-r7) の場合です。
$ kubectl run gentoo-musl --image=gentoo/stage3:amd64-musl-20220224 --tty -i sh
If you don't see a command prompt, try pressing enter.
sh-5.1# emerge --info
!!! Section 'gentoo' in repos.conf has location attribute set to nonexistent directory: '/var/db/repos/gentoo'
!!! Invalid Repository Location (not a dir): '/var/db/repos/gentoo'
WARNING: One or more repositories have missing repo_name entries:
/var/db/repos/gentoo/profiles/repo_name
NOTE: Each repo_name entry should be a plain text file containing a
unique name for the repository on the first line.
!!! It seems /run is not mounted. Process management may malfunction.
Portage 3.0.30 (python 3.9.9-final-0, unavailable, gcc-11.2.0, musl-1.2.2-r7, 5.10.90+ x86_64)
=================================================================
System uname: Linux-5.10.90+-x86_64-Intel-R-_Xeon-R-_CPU_@_2.20GHz-with-libc
KiB Mem: 4026068 total, 131520 free
KiB Swap: 0 total, 0 free
sh bash 5.1_p16
ld GNU ld (Gentoo 2.37_p1 p2) 2.37
dev-lang/python: 3.9.9-r1::gentoo, 3.10.0_p1-r1::gentoo
sys-devel/autoconf: 2.71-r1::gentoo
sys-devel/automake: 1.16.4::gentoo
sys-devel/binutils: 2.37_p1-r2::gentoo
sys-devel/libtool: 2.4.6-r6::gentoo
sys-kernel/linux-headers: 5.15-r3::gentoo (virtual/os-headers)
Repositories:
ACCEPT_LICENSE="* -@EULA"
CFLAGS="-O2 -pipe"
CHOST="x86_64-gentoo-linux-musl"
CONFIG_PROTECT="/etc /usr/share/gnupg/qualified.txt"
CONFIG_PROTECT_MASK="/etc/ca-certificates.conf /etc/env.d /etc/gentoo-release /etc/sandbox.d /etc/terminfo"
CXXFLAGS="-O2 -pipe"
DISTDIR="/var/cache/distfiles"
FEATURES="assume-digests binpkg-docompress binpkg-dostrip binpkg-logs buildpkg-live config-protect-if-modified distlocks ebuild-locks fixlafiles ipc-sandbox merge-sync multilib-strict network-sandbox news parallel-fetch pid-sandbox preserve-libs protect-owned qa-unresolved-soname-deps sandbox sfperms strict unknown-features-warn unmerge-logs unmerge-orphans userfetch userpriv usersandbox usersync xattr"
GENTOO_MIRRORS="http://distfiles.gentoo.org"
PKGDIR="/var/cache/binpkgs"
PORTAGE_TMPDIR="/var/tmp"
USE=""
Unset: ACCEPT_KEYWORDS, EMERGE_DEFAULT_OPTS, ENV_UNSET, PORTAGE_BINHOST, PORTAGE_BUNZIP2_COMMAND
sh-5.1# wget www.google.com
--2022-02-28 00:10:30-- http://www.google.com/
Resolving www.google.com... failed: Name does not resolve.
wget: unable to resolve host address 'www.google.com'
sh-5.1# nslookup www.google.com
sh: nslookup: command not found
sh-5.1# emerge --sync
!!! It seems /run is not mounted. Process management may malfunction.
>>> Syncing repository 'gentoo' into '/var/db/repos/gentoo'...
* Using keys from /usr/share/openpgp-keys/gentoo-release.asc
* Refreshing keys via WKD ... [ ok ]
!!! getaddrinfo failed for 'rsync.gentoo.org': [Errno -2] Name does not resolve
>>> Starting rsync with rsync://rsync.gentoo.org/gentoo-portage...
rsync: getaddrinfo: rsync.gentoo.org 873: Name does not resolve
rsync error: error in socket IO (code 10) at clientserver.c(137) [Receiver=3.2.3]
>>> Retrying...
!!! Exhausted addresses for rsync.gentoo.org
* IMPORTANT: 12 news items need reading for repository 'gentoo'.
* Use eselect news read to view new items.
Action: sync for repo: gentoo, returned code = 1
sh-5.1#
Alpine のときと同様、wget に失敗します。
なお、nslookup はデフォルトでは含まれていないため、Portage を使ってインストールする必要がありますが、名前解決に失敗するため emerge コマンドが機能しません。
次は Gentoo (5.10.90+) + glibc (glibc-2.33-r7) の場合です。
$ kubectl run gentoo-glibc --image=gentoo/stage3:amd64-systemd-20220224 --tty -i sh
If you don't see a command prompt, try pressing enter.
sh-5.1# emerge --info
!!! Section 'gentoo' in repos.conf has location attribute set to nonexistent directory: '/var/db/repos/gentoo'
!!! Invalid Repository Location (not a dir): '/var/db/repos/gentoo'
WARNING: One or more repositories have missing repo_name entries:
/var/db/repos/gentoo/profiles/repo_name
NOTE: Each repo_name entry should be a plain text file containing a
unique name for the repository on the first line.
!!! It seems /run is not mounted. Process management may malfunction.
Portage 3.0.30 (python 3.9.9-final-0, unavailable, gcc-11.2.0, glibc-2.33-r7, 5.10.90+ x86_64)
=================================================================
System uname: Linux-5.10.90+-x86_64-Intel-R-_Xeon-R-_CPU_@_2.20GHz-with-glibc2.33
KiB Mem: 4026068 total, 128684 free
KiB Swap: 0 total, 0 free
sh bash 5.1_p16
ld GNU ld (Gentoo 2.37_p1 p2) 2.37
dev-lang/python: 3.9.9-r1::gentoo, 3.10.0_p1-r1::gentoo
sys-devel/autoconf: 2.71-r1::gentoo
sys-devel/automake: 1.16.4::gentoo
sys-devel/binutils: 2.37_p1-r2::gentoo
sys-devel/libtool: 2.4.6-r6::gentoo
sys-kernel/linux-headers: 5.15-r3::gentoo (virtual/os-headers)
Repositories:
ACCEPT_LICENSE="* -@EULA"
CFLAGS="-O2 -pipe"
CONFIG_PROTECT="/etc /usr/share/gnupg/qualified.txt"
CONFIG_PROTECT_MASK="/etc/ca-certificates.conf /etc/env.d /etc/gentoo-release /etc/sandbox.d /etc/terminfo"
CXXFLAGS="-O2 -pipe"
DISTDIR="/var/cache/distfiles"
FEATURES="assume-digests binpkg-docompress binpkg-dostrip binpkg-logs buildpkg-live config-protect-if-modified distlocks ebuild-locks fixlafiles ipc-sandbox merge-sync multilib-strict network-sandbox news parallel-fetch pid-sandbox preserve-libs protect-owned qa-unresolved-soname-deps sandbox sfperms strict unknown-features-warn unmerge-logs unmerge-orphans userfetch userpriv usersandbox usersync xattr"
GENTOO_MIRRORS="http://distfiles.gentoo.org"
PKGDIR="/var/cache/binpkgs"
PORTAGE_TMPDIR="/var/tmp"
USE=""
Unset: ACCEPT_KEYWORDS, CHOST, EMERGE_DEFAULT_OPTS, ENV_UNSET, PORTAGE_BINHOST, PORTAGE_BUNZIP2_COMMAND
sh-5.1# wget www.google.com
--2022-02-28 00:17:16-- http://www.google.com/
Resolving www.google.com... 108.177.111.106, 108.177.111.103, 108.177.111.105, ...
Connecting to www.google.com|108.177.111.106|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: 'index.html'
index.html [ <=> ] 13.91K --.-KB/s in 0s
2022-02-28 00:17:16 (36.6 MB/s) - 'index.html' saved [14243]
sh-5.1# emerge --sync
... (略) ...
sh-5.1# emerge net-dns/bind-tools -q
...
>>> Verifying ebuild manifests
>>> Emerging (1 of 1) net-dns/bind-tools-9.16.22::gentoo
>>> Installing (1 of 1) net-dns/bind-tools-9.16.22::gentoo
>>> Recording net-dns/bind-tools in "world" favorites file...
...
sh-5.1# nslookup www.google.com
Server: 10.120.0.10
Address: 10.120.0.10#53
Non-authoritative answer:
Name: www.google.com
Address: 173.194.194.104
Name: www.google.com
Address: 173.194.194.147
Name: www.google.com
Address: 173.194.194.105
Name: www.google.com
Address: 173.194.194.103
Name: www.google.com
Address: 173.194.194.99
Name: www.google.com
Address: 173.194.194.106
** server can't find www.google.com: NXDOMAIN
sh-5.1#
こちらは wget に成功しています。
以上から、musl libc と glibc で名前解決に関する挙動が異なっていることがわかります。
バージョンが 3.12 までの Alpine であれば、GKE 1.22 + Node Local DNS Cache の環境であっても名前解決に成功します。
3.12 までの Alpine では musl libc 1.1 系が利用されており、1.2 系とは実装が異なるためです。
Alpine のリリースアナウンスでも 3.13 から musl libc 1.2 系 に変更されたことが記載されています。
musl libc のコミットを追いかけてみると、1.2.1 で A + AAAA ペアクエリに対する挙動が変更されていることを確認できます。
この変更は、初版の 1.2.0 にはバックポートされなかったようです。
なお、musl libc では getaddrinfo のデフォルトのアドレスファミリが AF_UNSPEC となっているため、変更しない限りは A + AAAA のペアクエリになります。
回避手段
では GKE 1.22 において、Alpine 3.13+ のコンテナが名前解決を行えるようにするにはどうすればよいでしょうか。
以下のような手段が考えられます。
- クラスタの Node Local DNS Cache を無効化する
- 該当するコンテナの resolv.conf を書き換えて Node Local DNS Cache を迂回する
- Alpine の使用をやめる
いずれもクラスタやアプリケーションの構成変更が必要になるため、GKE ユーザとしては対処が悩ましいところですね。
1 はキャッシュが効かなくなるため性能面の影響が懸念されるでしょう。
2 は設定の変更対象が多いと大変ですし、その他の NW 要件との干渉で適切に迂回できない場合も考えられます。
3 はユーザアプリケーションなら検討の余地があるかもしれませんが、ミドルウェアのコンテナが Alpine 3.13+ を使用している場合には対処が困難です。
Node Local DNS Cache の Corefile の設定を書き換えることも可能ですが、kube-system Namespace 内のリソースはコントロールプレーンの一部として Google 側が管理・変更を行うため、手動で書き換えたとしても再び上書きされてしまう可能性があります。
GKE 1.22 の Node Local DNS Cache のデフォルト設定が、AAAA クエリに対して NODATA で応答する、もしくは kube-dns / Cloud DNS への再帰問い合わせを許可してくれるようになれば、根本的な解決となるかもしれません。
なお、GKE Autopilot では Node Local DNS Cache が強制的に有効化されるため、Autopilot 環境の Alpine ユーザは軒並みこの影響を受けることになると思われます。
こちらは resolv.conf で迂回するか、Alpine の使用をやめるくらいしか対応方法がなさそうですね。
まとめ
以下の相性問題により、GKE 1.22 で Node Local DNS Cache を有効化すると 3.13 以上の Alpine が名前解決に失敗することを確認しました。
- GKE 1.22 の Node Local DNS Cache (1.21.4-gke.0) は AAAA に対して一律 NXDOMAIN を返す設定が追加されている
- Alpine 3.13+ は musl libc 1.2.1+ を使用しており、A + AAAA ペアクエリのいずれかで NXDOMAIN が返るとクエリ全体が失敗したものとして扱われる
お読み頂いた方のお役に立てば幸いです。
参考
GKE ノードプールのアップグレードを中断(キャンセル)する
GKE ノードプールのアップグレードがキャンセルできるようになっていたので試してみました。
現状はベータ版として提供されている機能になります。
公式ドキュメントの該当箇所はこちら。
検証
GKE では、アップグレードに限らずクラスタに対するオペレーション(作成・削除・アップグレードなど)はその都度オペレーション ID が割り振られるようになっており、gcloud container operations list コマンドで確認することができます。
cloudshell:~ $ gcloud container operations list ... NAME: operation-1642596393580-28fce564 TYPE: CREATE_CLUSTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T12:46:33.580352532Z END_TIME: 2022-01-19T12:50:24.97742246Z ...
検証対象のクラスタ sample-cluster の作成オペレーションが完了していることがわかります。
今回は、コントロールプレーン・ノードプールともに 1.21.5-gke.1302 から 1.21.6-gke.1500 にアップグレードします。
ノードプールはノード数 3 の状態で開始します。
ノードプールのアップグレードを行う前に、まずはコントロールプレーンがノードプールのアップグレード先のバージョンをサポートできるようアップグレードしておきます。

gcloud container operations list コマンドでオペレーションの状態を確認します。
cloudshell:~ $ gcloud container operations list ... NAME: operation-1642596393580-28fce564 TYPE: CREATE_CLUSTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T12:46:33.580352532Z END_TIME: 2022-01-19T12:50:24.97742246Z NAME: operation-1642599713836-a095ee51 TYPE: UPGRADE_MASTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: RUNNING START_TIME: 2022-01-19T13:41:53.836300031Z END_TIME: ...
コントロールプレーンのアップグレードが開始されていることがわかります。
今回検証するキャンセルの機能はノードプールのアップグレードが対象とされていますが、試しにこの状態でもオペレーションのキャンセルをリクエストしてみます。
GKE クラスタに対するオペレーションのキャンセルはベータ機能であるため、gcloud beta コマンドを使います。
gcloud beta container operations cancel コマンドのリファレンスは以下で確認することができます。
cloudshell:~ $ gcloud beta container operations cancel operation-1642599713836-a095ee51 Are you sure you want to cancel operation operation-1642599713836-a095ee51? Do you want to continue (Y/n)? Y ERROR: (gcloud.beta.container.operations.cancel) INVALID_ARGUMENT: Only node upgrade operations can be cancelled.
エラーになりました。
メッセージにもあるとおり、やはりノードプールのアップグレードのみがサポートされていることがわかります。
コントロールプレーンのアップグレードが完了したのち、ノードプールのアップグレードを行います。

gcloud container operations list コマンドでオペレーションの状態を確認します。
cloudshell:~ $ gcloud container operations list ... NAME: operation-1642596393580-28fce564 TYPE: CREATE_CLUSTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T12:46:33.580352532Z END_TIME: 2022-01-19T12:50:24.97742246Z NAME: operation-1642599713836-a095ee51 TYPE: UPGRADE_MASTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T13:41:53.836300031Z END_TIME: 2022-01-19T14:06:04.341528233Z NAME: operation-1642601615896-46119ad0 TYPE: UPGRADE_NODES LOCATION: asia-northeast1 TARGET: default-pool STATUS_MESSAGE: STATUS: RUNNING START_TIME: 2022-01-19T14:13:35.896076128Z END_TIME: ...
ノードのアップグレードは正常に開始されているようです。
では、一部のノードのアップグレードが完了したところを見計らってキャンセルしてみます。
コンソールではノードプールが以下のような状態となっていました。

ここで、先程と同様に gcloud beta container operations cancel コマンドを実行します。
cloudshell:~ $ gcloud beta container operations cancel operation-1642601615896-46119ad0
Are you sure you want to cancel operation operation-1642601615896-46119ad0?
Do you want to continue (Y/n)? Y
Cancelation of operation operation-1642601615896-46119ad0 has been requested. Please use gcloud container operations describe operation-1642601615896-46119ad0 to check if the operation has been canceled successfully.
detail: 'Updating default-pool, done with 1 out of 3 nodes (33.3%): 1 being processed'
name: operation-1642601615896-46119ad0
operationType: UPGRADE_NODES
progress:
metrics:
- intValue: '3'
name: NODES_TOTAL
- intValue: '0'
name: NODES_FAILED
- intValue: '1'
name: NODES_COMPLETE
- intValue: '1'
name: NODES_DONE
- intValue: '0'
name: NODE_PDB_DELAY_SECONDS
selfLink: https://container.googleapis.com/v1beta1/projects/************/locations/asia-northeast1/operations/operation-1642601615896-46119ad0
startTime: '2022-01-19T14:13:35.896076128Z'
status: ABORTING
targetLink: https://container.googleapis.com/v1beta1/projects/************/locations/asia-northeast1/clusters/sample-cluster/nodePools/default-pool
zone: asia-northeast1
キャンセルのリクエストが受け付けられました。
detail の内容はコンソールで確認したノードプールの状態と一致しています。
この時点では status が ABORTING となっており、キャンセルが成否を問わずリクエストの受付が完了した時点でコマンドへの応答が行われていることがわかります。
メッセージの指示にあるとおり、キャンセルの成否は別途 gcloud container operations describe コマンドで確認する必要があります。
キャンセルのリクエストをかけたのち間を置かずに確認しましたが、既にキャンセルのリクエストは成功していました。
結果は下記のように出力されました。
cloudshell:~ $ gcloud container operations describe operation-1642601615896-46119ad0
clusterConditions:
- canonicalCode: CANCELLED
message: 'Operation was aborted: operation-1642601615896-46119ad0.'
detail: 'Operation was aborted: operation-1642601615896-46119ad0.'
endTime: '2022-01-19T14:21:01.520708481Z'
error:
code: 1
message: 'Operation was aborted: operation-1642601615896-46119ad0.'
name: operation-1642601615896-46119ad0
operationType: UPGRADE_NODES
progress:
metrics:
- intValue: '3'
name: NODES_TOTAL
- intValue: '0'
name: NODES_FAILED
- intValue: '2'
name: NODES_COMPLETE
- intValue: '2'
name: NODES_DONE
- intValue: '0'
name: NODE_PDB_DELAY_SECONDS
selfLink: https://container.googleapis.com/v1/projects/************/locations/asia-northeast1/operations/operation-1642601615896-46119ad0
startTime: '2022-01-19T14:13:35.896076128Z'
status: DONE
statusMessage: 'Operation was aborted: operation-1642601615896-46119ad0.'
targetLink: https://container.googleapis.com/v1/projects/************/locations/asia-northeast1/clusters/sample-cluster/nodePools/default-pool
zone: asia-northeast1
gcloud beta container operations list コマンドでも確認してみます。
cloudshell:~ $ gcloud container operations list ... NAME: operation-1642596393580-28fce564 TYPE: CREATE_CLUSTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T12:46:33.580352532Z END_TIME: 2022-01-19T12:50:24.97742246Z NAME: operation-1642599713836-a095ee51 TYPE: UPGRADE_MASTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T13:41:53.836300031Z END_TIME: 2022-01-19T14:06:04.341528233Z NAME: operation-1642601615896-46119ad0 TYPE: UPGRADE_NODES LOCATION: asia-northeast1 TARGET: default-pool STATUS_MESSAGE: Operation was aborted: operation-1642601615896-46119ad0. STATUS: DONE START_TIME: 2022-01-19T14:13:35.896076128Z END_TIME: 2022-01-19T14:21:01.520708481Z NAME: operation-1642602132989-39493995 TYPE: UPDATE_CLUSTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T14:22:12.989734846Z END_TIME: 2022-01-19T14:22:13.741871596Z ...
キャンセルが完了していることが確認できました。
アップグレードは最後まで完了しなかったため、コンソール上の当該ノードプールはアップグレード前のバージョンとして表示されています。

しかし、実際には一部のノードのアップグレードが完了していたため、ノードのバージョンが混在した状態となっています。
cloudshell:~ $ kubectl get node NAME STATUS ROLES AGE VERSION gke-sample-cluster-default-pool-4a3a874a-0mqn Ready <none> 16m v1.21.6-gke.1500 gke-sample-cluster-default-pool-7a3668ce-5tb7 Ready <none> 100m v1.21.5-gke.1302 gke-sample-cluster-default-pool-8005ab02-2iq1 Ready <none> 10m v1.21.6-gke.1500 gke-sample-cluster-default-pool-8005ab02-79ff Ready,SchedulingDisabled <none> 101m v1.21.5-gke.1302
コンソールでは以下のように見えています。

ここで、元のノードプールのサイズは 3 でしたが、キャンセル後のノード数は 4 に増えています。
これはサージアップグレードを有効化(max surge: 1)していたためで、アップグレード中に新しいノードを追加し、そのセットアップが完了して古いノードを cordon したあたりでキャンセルが受け付けられたようです。

ではこの状態でもう一度アップグレードをリクエストするとどうなるか試してみます。
先ほどと同じようにノードプールのアップグレードを開始します。
4 台のノードに対してアップグレードのプロセスを開始していることが確認できます。

gcloud beta container operations list コマンドでも確認してみます。
cloudshell:~ $ gcloud container operations list ... NAME: operation-1642596393580-28fce564 TYPE: CREATE_CLUSTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T12:46:33.580352532Z END_TIME: 2022-01-19T12:50:24.97742246Z NAME: operation-1642599713836-a095ee51 TYPE: UPGRADE_MASTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T13:41:53.836300031Z END_TIME: 2022-01-19T14:06:04.341528233Z NAME: operation-1642601615896-46119ad0 TYPE: UPGRADE_NODES LOCATION: asia-northeast1 TARGET: default-pool STATUS_MESSAGE: Operation was aborted: operation-1642601615896-46119ad0. STATUS: DONE START_TIME: 2022-01-19T14:13:35.896076128Z END_TIME: 2022-01-19T14:21:01.520708481Z NAME: operation-1642602132989-39493995 TYPE: UPDATE_CLUSTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T14:22:12.989734846Z END_TIME: 2022-01-19T14:22:13.741871596Z NAME: operation-1642603081158-8a2f2134 TYPE: UPGRADE_NODES LOCATION: asia-northeast1 TARGET: default-pool STATUS_MESSAGE: STATUS: RUNNING START_TIME: 2022-01-19T14:38:01.158573778Z END_TIME: ...
その後、アップグレードが完了すると、コンソールでは以下のように表示されました。

改めて gcloud beta container operations list コマンドでも確認してみます。
cloudshell:~ $ gcloud container operations list NAME: operation-1642596393580-28fce564 TYPE: CREATE_CLUSTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T12:46:33.580352532Z END_TIME: 2022-01-19T12:50:24.97742246Z NAME: operation-1642599713836-a095ee51 TYPE: UPGRADE_MASTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T13:41:53.836300031Z END_TIME: 2022-01-19T14:06:04.341528233Z NAME: operation-1642601615896-46119ad0 TYPE: UPGRADE_NODES LOCATION: asia-northeast1 TARGET: default-pool STATUS_MESSAGE: Operation was aborted: operation-1642601615896-46119ad0. STATUS: DONE START_TIME: 2022-01-19T14:13:35.896076128Z END_TIME: 2022-01-19T14:21:01.520708481Z NAME: operation-1642602132989-39493995 TYPE: UPDATE_CLUSTER LOCATION: asia-northeast1 TARGET: sample-cluster STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T14:22:12.989734846Z END_TIME: 2022-01-19T14:22:13.741871596Z NAME: operation-1642603081158-8a2f2134 TYPE: UPGRADE_NODES LOCATION: asia-northeast1 TARGET: default-pool STATUS_MESSAGE: STATUS: DONE START_TIME: 2022-01-19T14:38:01.158573778Z END_TIME: 2022-01-19T14:44:55.142139747Z ...
kubectl get nodes コマンドの実行結果は以下のとおりです。
cloudshell:~ $ kubectl get nodes NAME STATUS ROLES AGE VERSION gke-sample-cluster-default-pool-4a3a874a-0mqn Ready <none> 31m v1.21.6-gke.1500 gke-sample-cluster-default-pool-7a3668ce-yhk7 Ready <none> 4m37s v1.21.6-gke.1500 gke-sample-cluster-default-pool-8005ab02-2iq1 Ready <none> 26m v1.21.6-gke.1500
ノード数は 3 となっており、すべてのノードが v1.21.6-gke.1500 にアップグレードされたことがわかります。
ノードの作成時間からして、中断した 1 回目のアップグレードでアップグレードが完了したノードはそのまま使われる(再作成はしない)ようですね。
また、1 回目のアップグレードと 2 回目のアップグレードは独立したオペレーションなのでノードプールのサイズは 4 のままアップグレードが完了するのではと思ったのですが、実際には元のノードプールのサイズに収束したことが確認できました。
キャンセルの使い所
今回試したアップグレードのキャンセルの機能は、例えばノードプールのアップグレード中に障害が発生した場合などに活用できそうです。
従来、ノードプールのアップグレードが開始されるとクラスタはアンタッチャブルな状態となってしまうため、アップグレード中に障害が発生するなどして特定のノードを切り離したいという状況下においてもユーザにはアップグレードの完了を待つしか選択肢がありませんでした。
アップグレードがキャンセルできるようになったことで、アップグレードが長時間化する状況下でも、ある程度短い待ち時間でクラスタへの操作権をユーザに戻すことができるようになりました。
まとめ
GKE におけるノードプールのアップグレードをキャンセルする機能について基本的な動作の確認をしました。
アップグレードが想定外に長期化するようなシチュエーションでも、「いざとなれば中断できる」という選択肢ができたことで安心感してアップグレードの完了を待てそうです。
CKS (Certified Kubernetes Security Specialist) を取得しました
CNCF (Cloud Native Computing Foundation) が提供している Kubernetes の認定資格、CKS (Certified Kubernetes Security Specialist) を取得しました。
受験準備や参照したリソースについて書き残しておきたいと思います。
過去に CKAD, CKA を取得した際の受験記録は こちら です。
試験概要
Linux Foundation 傘下で Kubernetes をはじめ様々な Cloud Native 関連の OSS プロジェクトをホストしている CNCF (Cloud Native Computing Foundation) という組織があり、そちらから提供されている監督付きのオンライン試験となっています。
CKS (Certified Kubernetes Security Specialist)
Kubernetes のプラットフォームとコンテナベースのアプリケーションに関するセキュリティスペシャリストを対象とした試験です。
受験するためには CKA の認定を保持している必要があります。
- 試験時間:2 時間
- 問題数:15 ~ 20 問
- 受験料:$375
- 試験官との応対言語:英語
- 試験問題の言語:英語・日本語・中国語を適宜切り替え可能
- 受験したときの Kubernetes のバージョン:v1.22
試験官との応対、および試験の言語
CKS では試験官との応対は英語で行います。
日本語話者の試験官を希望する場合は、CKS ではなく CKS-JP に申し込む必要があるようです。
CKS で受験した場合でも、試験問題は日本語を選択可能です。
したがって英語を使う必要があるのは試験前の環境確認や注意事項の案内など簡単なやりとりに限られますが、不安があれば CKS-JP での申し込みを検討されても良いかもしれません。
このあたりは CKAD, CKA と同じですね。
試験概要
詳しくは公式サイトをご確認頂くのが良いかと思いますが、特に下記のドキュメントは目を通してから受験されることをおすすめします。
試験のレギュレーションをよく理解しておくことで、限られた時間で効率よく問題を解いてゆくことができると思います。
- Candidate Handbook
- カリキュラムの概要
- Exam Tips
- Frequently Asked Questions
再試験ポリシー
試験に落ちた場合、1 回まで再受験が可能となっているようです。
そのため、ある程度準備ができたところで試験内容のレベル感を把握するために一度受験してみる、といったアプローチも良いかと思います。
私は 1 回目の受験で合格したため利用することはありませんでした。
おすすめの学習リソース
Docker / Kubernetes 開発・運用のためのセキュリティ実践ガイド
Kubernetes やコンテナアプリケーションのセキュリティ対策に関するベストプラクティスがまとめられている書籍です。
試験対策を目的とした書籍ではありませんが、関連するトピックが多数含まれるほか、解説も丁寧で実践的な内容となっています。
CKS の受験にあたり何から手を付ければ良いか迷われている方は、まずはこの本を通読するところから始めるのがおすすめです。
Kubernetes 完全ガイド 第2版
言わずとしれた Kubernetes 関連の代表的な参考書です。
第 2 版が出版され、Kubernetes v1.18 をベースとした内容にアップデートされています。
Kubernetes の機能が網羅的に解説されており、今回 CKS の試験対策としては辞書的な使い方で活用しました。
Killer Shell (Killer.sh) CKS Simulator
CKS の本番の試験よりも難しいとされる試験シミュレータです。
CKS の試験登録を行うと、2 回分(1 回あたり 36 時間有効) の使用が可能で、有効な時間内であれば何度でも環境をリセットすることができるようになっています。
なお、このシミュレータは何度受験しても同じ内容・同じ出題順序となっています。
CKS Curated Resources
問題集やチュートリアルではないのですが、CKS の受験にあたって注意すべき事項と必要な基礎知識がまとめられていますので、一読しておくことをおすすめします。
私は利用しませんでしたが、Udemy で提供されている CKS 試験対策コースはこのサイトのリンクから割引で購入できます。
受験準備
学習の流れ
まずは『Docker / Kubernetes 開発・運用のためのセキュリティ実践ガイド』をひととおり読みました。
ここで Kubernetes やコンテナアプリケーションのセキュリティに関する概要レベルの全体像が掴めたことで、後の学習がスムーズになったと思います。
その後、Killer Shell (Killer.sh) CKS Simulator を 2 周して試験に挑みました。
試験対策という観点では、Killer Shell の問題を解き、不明点を再学習するというサイクルを繰り返したのが効いたと思います。
受験場所
試験はオンラインで実施されるため、受験場所は受験者自身があらかじめ確保しておく必要があります。
私の場合、今回は自宅で受験しました。
受験するときのテーブル上には、許可されたもの(ディスプレイ、キーボード、マウスetc.)以外は一切置くことができません。
過去の CKAD, CKA の受験時もそうだったかは失念してしまったのですが、今回、ラベルを外した状態の水のペットボトルはテーブルに置くことが許可されていました。
また、私はキーボードとマウスにそれぞれアームレストを使っているのですが、こちらも利用可能でした。
Kubernetes.io, Falco, Trivy などの参照可能ドキュメントの活用
試験中には Kubernetes の公式ドキュメントに加え、Falco や Trivy のドキュメントページを参照することができますが、試験時間を考えるとその場で新しい知識を仕入れている余裕はないと思います。
私の場合は、参照するであろういくつかのページをブラウザのブックマークに登録しておくようにしました。
受験時の所感
試験の難易度
Kubernetes やコンテナベースのアプリケーションのセキュリティに関して幅広いトピックが出題され、全体の難しさとしては CKA と同じくらいのレベルではないかと感じました。
セキュリティに関して幅広い出題範囲が設けられていますが、基本をよく理解しておけば回答可能な問題が多く、重箱の隅をつつくような問題はなかったという印象でした。
問題ごとに配点の目安となるパーセンテージが明記されていますので、これを参考に回答順序を考えても良いでしょう。
ブラウザの制限
公式の受験要項にも記載されていますが、Kubernetes.io の公式ドキュメント以外の Web ページにアクセスしないことや、ドキュメント参照のために複数のタブを開かないことは受験者自身の努力で遵守する必要があります。
特に試験で利用する端末にアクセス制限や開くタブ数の制限が設定されるわけではないため、ブックマークなどを利用する際はうっかり許可されていないページにアクセスしないよう注意が必要です。
おわりに
幅広い出題範囲のおかげ(?)で、Kubernetes やコンテナアプリケーションのセキュリティに関する様々な知識を学習・再認識する機会になりました。
CKA 認定保持者を対象とした試験のため、受験プロセスには慣れている方が多いかと思いますが、コンソールや細かなレギュレーションのアップデートなどもあるため、受験要項などの公式ドキュメントはよく読んだうえで受験されることをおすすめします。
GKE Autopilot の Spot Pod とプリエンプションの関係
Google Cloud Platform Advent Calendar 2021 の 9 日目の投稿です。
(執筆を予定されていた方が投稿されなかったため代わりに投稿させて頂きます)
先日、GKE Autopilot で Spot Pod が利用可能になりました(執筆時点ではプレビュー)。
Google Cloud の Blog に投稿されたアナウンスの記事は こちら 。
中断可能なワークロードに対して大幅なコスト削減が期待できるオプションですが、活用にあたっていくつかの制約を理解しておく必要があり、この記事ではそのひとつとして Spot Pod のシャットダウン時の仕様について触れたいと思います。
Spot Pod とプリエンプション
Spot Pod は、Spot Pod の利用をリクエストするための nodeSelector または affinity を Pod のテンプレートに付与することで、GKE Autopilot が GCE の Spot VM を自動でプロビジョニングして Spot Pod をデプロイする、というかたちで使用されます。
GKE 1.20 以降の Preemptible VM / Spot VM では、Graceful Node Shutdown が有効化&設定されています。
利用している Spot VM がプリエンプションの対象となった場合は、Pod を安全に終了させるための猶予期間がリクエストできるようになっており、最長 25 秒 ※ の猶予期間をリクエスト可能です。
※ Autopilot ワークロードの Spot Pod をリクエストする
https://cloud.google.com/kubernetes-engine/docs/how-to/autopilot-spot-pods#request-spot-pods
プリエンプションでの Spot Pod の最大猶予期間は 25 秒です。
このリクエストできる期間の長さは Graceful Node Shutdown の設定によって上限が決まる仕組みになっています。
実際の設定を見てみましょう。
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
enabled: true
x509:
clientCAFile: /etc/srv/kubernetes/pki/ca-certificates.crt
authorization:
mode: Webhook
cgroupRoot: /
clusterDNS:
- 10.12.0.10
clusterDomain: cluster.local
enableDebuggingHandlers: true
evictionHard:
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
pid.available: 10%
featureGates:
DynamicKubeletConfig: false
ExecProbeTimeout: false
GracefulNodeShutdown: true
InTreePluginAWSUnregister: true
InTreePluginAzureDiskUnregister: true
InTreePluginOpenStackUnregister: true
InTreePluginvSphereUnregister: true
RotateKubeletServerCertificate: true
kernelMemcgNotification: true
kind: KubeletConfiguration
kubeReserved:
cpu: 1060m
ephemeral-storage: 41Gi
memory: 1019Mi
readOnlyPort: 10255
serverTLSBootstrap: true
shutdownGracePeriod: 30s
shutdownGracePeriodCriticalPods: 5s
staticPodPath: /etc/kubernetes/manifests
Autopilot ではノードの設定が参照できないため、上記では GKE Standard で Spot VM としてプロビジョニングしたノードの kubelet の設定を参照しています(kubelet v1.21.5-gke.1302, cos-containerd, Spot VM の設定で GKE Standard にプロビジョニングしたノードの kubelet-config )。
Autopilot がプロビジョニングする Spot VM と全く同じ設定かどうかは確認する術がありませんが、ドキュメントを読む限り Graceful Node Shutdown まわりの設定は同じような設定になっていると考えても良さそうです。
設定内容を見てみると、kubelet の featureGates で Graceful Node Shutdown が有効化されています。
Graceful Node Shutdown に関連するパラメータは以下のふたつです。
- shutdownGracePeriod: 30s
- shutdownGracePeriodCriticalPods: 5s
Kubernetes の Graceful Node Shutdown のドキュメント ※ を読むと、ノードのプリエンプション時に Pod がリクエスト可能な terminationGracePeriodSeconds の最長期間は、CriticalPods と呼ばれるシステム系の Pod(Pod Priority が system-cluster-critical または system-node-critical)と、それ以外の Pod を区別して設定できるようになっています。
通常の(システム系以外の)Pod については、 shutdownGracePeriod の値からshutdownGracePeriodCriticalPods の値を引いた残り時間が、リクエスト可能な terminationGracePeriodSeconds の最長期間となります。
※ Graceful node shutdown
https://kubernetes.io/docs/concepts/architecture/nodes/#graceful-node-shutdown
GKE 1.20 以降の Preemptible VM / Spot VM では、上記の設定により (shutdownGracePeriod) - (shutdownGracePeriodCriticalPods) = 25 秒 が terminationGracePeriodSeconds でリクエスト可能な最長期間であることがわかります。
これが Spot Pod や、Spot VM で実行する Pod の terminationGracePeriodSeconds の上限としてドキュメントに記載されているということですね。
まとめ
Spot Pod のシャットダウン時の仕様と、(GKE Standard の Spot VM の設定から得られる推測を含みながらではありますが)それを実装している Graceful Node Shutdown の設定を確認しました。
Spot Pod のシャットダウンについては以下を認識しておくと良いでしょう。
- Spot Pod は載っているノードのプリエンプションが発生した際に Pod を安全に終了させるための猶予期間が指定できる(terminationGracePeriodSeconds)
- Spot Pod の terminationGracePeriodSeconds は最大 25 秒がリクエストでき、それ以上の値を指定しても無視される
- Spot Pod の terminationGracePeriodSeconds はあくまでもリクエストであり、指定しても必ずその猶予期間が確保されるとは限らない
以上です。
あなたにぴったりな Anthos Service Mesh を見つけよう
Google Cloud Platform Advent Calendar 2021 の 1 日目の記事です。
Anthos Service Mesh (以下、ASM) は Google Cloud が提供しているマネージドサービスメッシュです。
ASM には今年1年で多くのアップデートがありました。
GCP 以外の環境 (他のパブリッククラウドやオンプレミス) でも利用できるという Anthos のコンセプトにも関係しているのか、今年の ASM のアップデートでは実行環境やプロジェクトの要件に応じた複数の利用形態が登場しています。
選択肢が増えたことでドキュメントも拡充され、分量が増えているため、どのユースケースにどの利用形態が向いているのか、またどのオプションがどの利用形態で利用できるのか、といった情報を端的に掴むのがやや難しい面もあるのではないかと思います。
そこで今回は、ASM の利用形態と想定されるユースケースの違いについてざっくりと概要をご紹介し、これから ASM の導入を検討されている方に向けてヒントとなる情報を記せればと考えました。
なお、この記事では、GCP 上の GKE (公式ドキュメントでいうところの GKE clusters on Google Cloud) で利用する ASM の話にスコープを絞ります。
各構成の概要
記事執筆時点 (2021年11月29日) では、各構成の概要は以下のようになっています。
表に続いて、構成間の主な違いや共通点を説明します。
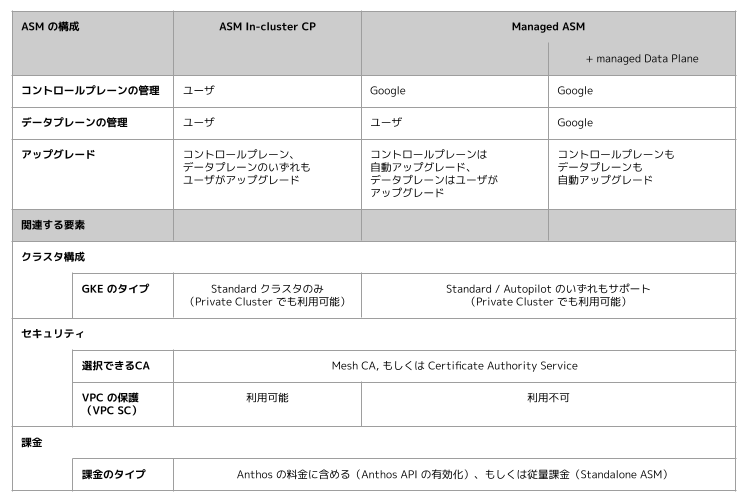
構成間の主な違い
ASM In-cluster Control Plane (以下、ASM In-cluster CP) はコントロールプレーン (Istiod) をユーザのクラスタ内にデプロイする利用形態となっています。
従来から提供されてきた ASM の構成であり、Istiod のアップグレードタイミングやキャパシティを自分たちで制御したい場合に適しています。
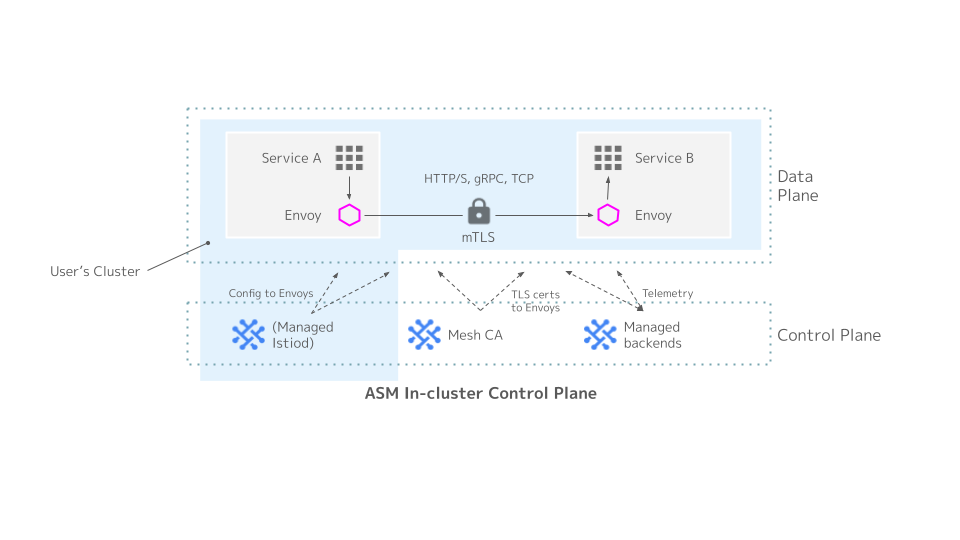
Managed ASM はコントロールプレーン (Istiod) を Google が管理する新しい利用形態です。
以下のイメージ図に示すように、コントロールプレーン (Istiod) がユーザのクラスタにデプロイされずとも、ASM を利用することができます。
Managed ASM では Istiod のアップグレードやキャパシティ管理をユーザが考慮する必要がなくなります。
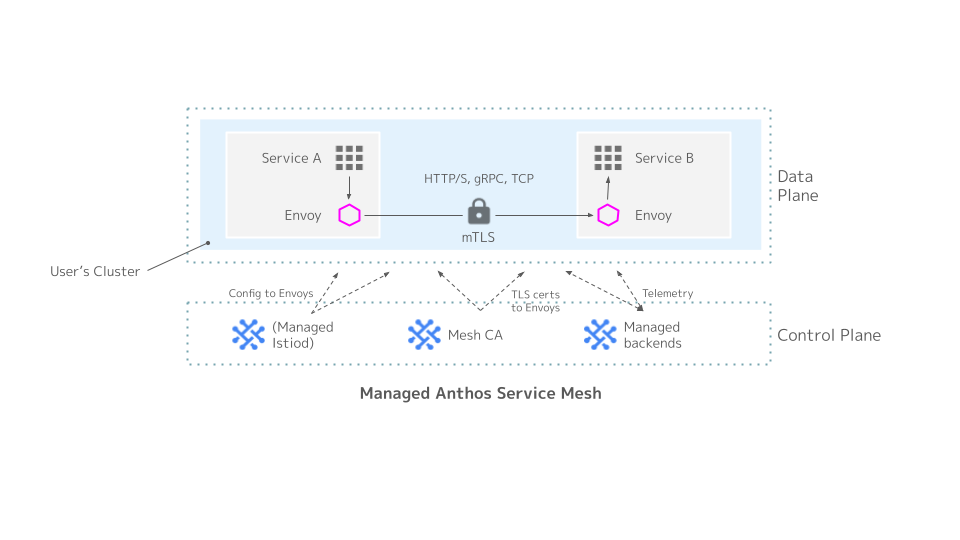
加えて、Managed ASM では Managed Data Plane の機能を利用することで、データプレーンにあたる Istio-proxy (Envoy) サイドカーのアップグレードを自動化することができます。
この構成では、以下のイメージ図に示すように、Data Plane Controller というコンポーネントがユーザのクラスタにデプロイされます。
Managed ASM のコントロールプレーンがアップグレードされる際に、併せてデータプレーンもアップグレードされます。
関連する要素
GKE のタイプ
GKE には現在、ノードの管理をユーザが行う Standard と、ノードの管理が不要になる Autopilot の 2 つの利用形態があります。
ASM In-cluster CP を利用する場合は、GKE が Standard クラスタである必要があります。
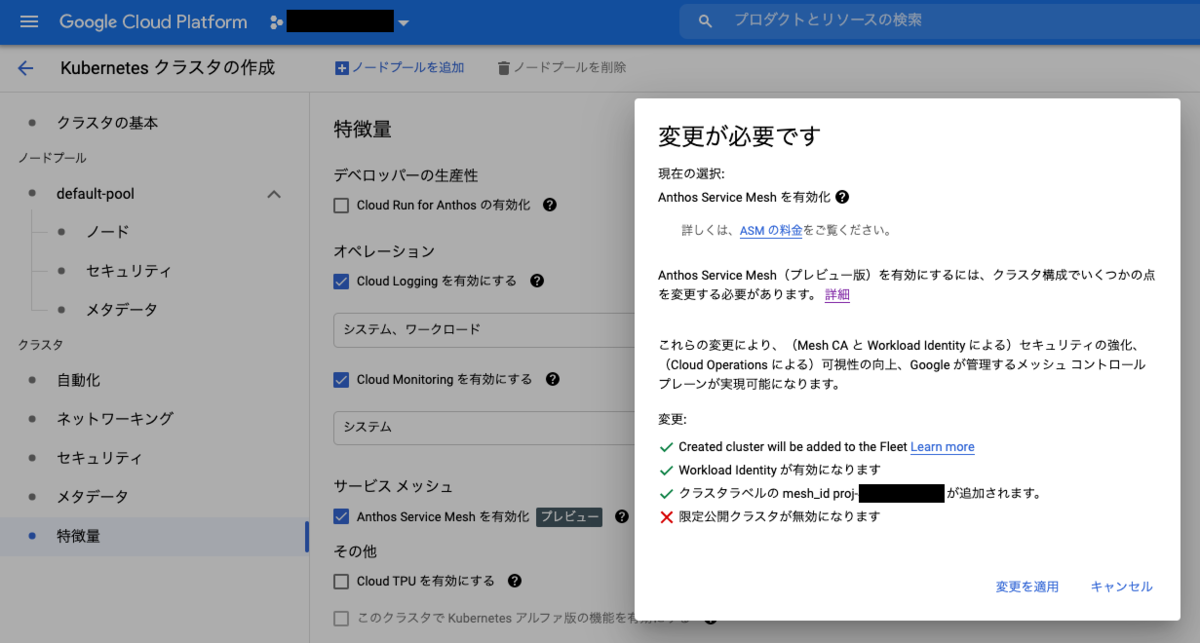
Managed ASM を利用する場合は、GKE クラスタの構成に制限がありません。つい先日までは、Autopilot では利用できない、Private Endpoint のみの Private Cluster (限定公開クラスタ) では利用できない、といった制限がありましたが、最新の 1.11.x では Managed ASM が全ての GKE クラスタの構成をサポートするようになりました。
https://cloud.google.com/service-mesh/docs/release-notes#November_19_2021
セキュリティ
セキュリティ関連では、CA の構成と VPC Service Controls を取り上げます。
CA はオープンソースの Istio の場合 Istio CA (以前の Citadel) が利用されますが、ASM では Mesh CA というマネージドの CA が提供されています。
ASM In-cluster CP では、デフォルトで Mesh CA を利用する構成となりますが、ASM をインストールする際のオプションで Certificate Authority Service (以下、CAS) を利用することも可能です。
CAS はプライベート CA を Google マネージドなインフラストラクチャで管理できるようにするためのサービスです。
Managed ASM はこれまで Mesh CA のみがサポートされていましたが、最新の 1.11.x では CAS もサポートされるようになりました。
(最新のリリースによって構成間の差異が無くなってしまった部分ではあるのですが、まだあまり知られていない変更点かと思いましたのでここで取り上げさせて頂きました)
VPC Service Controls (以下、VPC SC) は、リソースアクセスの論理的な境界を設けることで、境界内の GCP リソースのデータを保護する機能です。
機微情報を扱うアプリケーションなどで利用されることが多い機能のひとつとなっています。
ASM を構成した GKE や、Mesh CA もまた、GCP リソースのひとつであるため、(サポートされていれば) VPC SC の境界内に含めることができます。
ASM In-cluster CP がインストールされた GKE は VPC SC のサポート対象であるため、VPC SC でリソースを保護することが可能です。
一方、Managed ASM はまだサポートされていないため、VPC SC が利用できません。
なお、VPC SC のサポート対象リソースは以下で確認できます。
https://cloud.google.com/vpc-service-controls/docs/supported-products
課金
課金については ASM In-cluster CP と Managed ASM で利用できる選択肢に違いがないのですが、ASM を知るひとつの材料になると思いますのでここでご紹介したいと思います。
ASM は Anthos スイートの機能のひとつであり、以前は Anthos としての契約(Anthos API の有効化)を行うことでしか利用できませんでした。
Anthos の契約の一部として ASM を利用する場合には、Anthos 全体の利用料金の中に ASM の課金も含まれるようになっていましたが、今年のアップデートで Standalone ASM という ASM だけを利用する課金形態が追加されました。
これにより、Anthos のその他の機能は不要だがマネージドサービスメッシュだけ利用したい、といったユーザでも、Anthos の契約をせず従量課金で気軽に ASM を利用できるようになっています。
ASM In-cluster CP と Managed ASM のどちらであっても、Anthos API を有効化しての課金と、Standalone ASM での従量課金 の両方に対応しています。
構成を問わず共通して利用できる機能
mTLS の強制や、Ingress/Egress Gateway など、Istio としての基本的な機能は ASM In-cluster CP と Managed ASM のどちらでも利用可能です。
また、Cloud Operations (Cloud Monitoring, Cloud Logging, Cloud Trace, etc.) との統合や、Multi Cluster Service / Multi Cluster Ingress の利用といった Google Cloud の他の機能との統合も、多くの場合は ASM In-cluster CP と Managed ASM のどちらでも対応されています。
ユースケース
上記に示したように、現在の ASM には (Google Cloud の GKE で利用する場合だけでも) 複数の構成の選択肢があります。
以下では、いくつかのユースケースを提示しながら、各要件に合った ASM の構成をご紹介したいと思います。
ケース1. 世の中でより実績のある構成を求める場合
→ GKE Standard + ASM In-cluster CP + MeshCA
ASM のローンチ当初からサポートされてきた構成であり、GKE Autopilot や Managed ASM の登場以前は ASM と言えばこの構成を指していました。
Web で公開されている情報も ASM の利用形態の中で最も多く、 (私見ですが) 最も標準的な ASM の利用形態と言えるのではないかと思います。
構成上の制約が少なく、Private Cluster や VPC SC を使ったエンタープライズ向けの利用にもおすすめです。
この構成では GKE, ASM それぞれにアップグレードやキャパシティをユーザが管理してゆく必要があります。
GKE, ASM のアップグレードについては CloudNative Days Tokyo 2021 に登壇した際の資料で詳しくご紹介していますので、ご興味あればご参照頂ければと思います。
ケース2. とにかく一番手軽に使える ASM が欲しい場合
→ GKE Autopilot + Managed ASM + managed Data Plane + MeshCA + Standalone ASM
GKE, ASM の運用負荷が最小となる構成です。
GKE は Autopolot の場合リリースチャネルの利用が必須となるため、ユーザが GKE のコントロールプレーンおよびデータプレーン(ノード)のアップグレードを検討する必要はありません。
ASM もコントロールプレーンが Google によって管理され、コントロールプレーンの構成に伴ってデータプレーンも自動アップグレードされるため、ユーザによるアップグレードの検討は不要です。
Istio の各種機能を、最もインフラを意識せずに利用できる構成とも言えるのではないでしょうか。
CA は Mesh CA を利用することで証明書の管理も Google に任せることができ、Standalone ASM であれば Anthos API の有効化も不要です。
最近、Managed ASM はコンソールの GKE クラスタ作成フォームからも有効化できるようになりましたので、セットアップも非常に簡単化されています。
まずは ASM を試してみたい、という方におすすめです。
ケース3. 可能な限りマネージドな領域を減らしたい場合
→ GKE Standard (+ Private Cluster) + ASM In-cluster CP + CAS
一見マネージドサービスの考え方とは反するように思えるかもしれませんが、GKE + ASM という構成を使いつつも可能な限り自分たちでコンポーネントのバージョンを制御したいという場合はあり得ます。
例えば以下のような要件が考えられます:
- 運用ルール上、システムコンポーネントのバージョンを記録・管理しており、自動でバージョンが上がってしまうことは極力避けたい ※
- 障害発生時に再現試験などを行うため、システムコンポーネントのバージョンを固定したい
- 業界標準や法規制等の対応で、サービスメッシュ内の通信の暗号化 (mTLS) にプライベート CA を用いる必要がある
(※ GKEのコントロールプレーンは、リリースチャネルを利用していない場合でもパッチレベルでは自動アップグレードが走ります)
マネージドな領域を減らしてでも、その他のメリット(Istio の設計や運用にあたって Google のサポートを受けられる、オープンソースの Istio のコミュニティサポートよりも長い期間ひとつの ASM バージョンを運用できる等)を理由に GKE + ASM の構成を採用したい、というケースはあると思いますので、ASM がエンタープライズで利用される場合にはこういった構成も選択肢のひとつになると考えられます。
まとめ
オプションを含めて様々な選択肢が採用できるになった ASM の現状と、いくつかのユースケースにおいて候補となる GKE, ASM の構成をご紹介しました。
これから ASM の利用を検討されている方々の参考になれば幸いです。
なお、この記事では主な機能の違いを示し、現在の ASM の概要をお伝えすることを目的としました。
選択可能な全機能のサポート状況を網羅的に把握されたい場合は下記の公式ドキュメントをご参照ください。
https://cloud.google.com/service-mesh/docs/supported-features
https://cloud.google.com/service-mesh/docs/supported-features-mcp
Microsoft Certified: Azure Solutions Architect Expert を更新しました
以前取得した Azure Solutions Architect Expert の更新プログラムが受けられるようになっていたので、資格の有効期限を延長してきました。
更新の流れや資格のアップデート情報をお伝えしたいと思います。

Azure Solutions Architect Expert などの Microsoft のロールベース認定資格は、専用の更新プログラムを受験することで有効期限の延長を行う方式となっています。
テストセンター等で取得時と同じ試験の再受験をする必要はありません。
私は Azure Solutions Architect Expert を 2019 年 5 月に取得したのですが、今年に入って有効期限が半年ほど延長される措置があり、例外的に取得から 2 年半での更新となりました。
当時の受験記録は こちら 。
更新の流れ
資格の有効期限まで 6 ヶ月を切ると、認定資格のダッシュボードに「更新」のボタンが表示されます。
ボタンをクリックすると更新プログラムのページが表示され、「更新評価を受ける」のボタンを押すとオンライン試験の受験を開始できます(ボタンを押すと確認などなくいきなり試験が始まりますのでご注意ください)。
更新前にスクリーンショットを撮り忘れてしまったため、別の資格で恐縮ですが、更新プログラムのページは以下のようになっています。

試験が終わるとすぐに結果が表示され、ほどなくしてダッシュボード上の有効期限の表示も更新されます。
有効期限の更新は元の期限から 1 年間延長される形式となっているようなので、早めに更新の評価を受けても損はなさそうです。
私は何の準備もなく更新評価を受け始めてしまったのですが、ページ下部には更新評価の試験に関係する Microsoft Learn のモジュールがリストされていますので、スキルのアップデートに不安がある領域があれば事前に予習することも可能となっているようです。
試験概要
私が受験した際には以下のような試験となっていました。
- 試験時間: 45 分
- 問題数 : 26 問
- 合格基準: 65 %
落ちた場合は再受験が何度でも可能と記載されていました。
ただし、前の受験から 24 時間以上の間隔を空ける必要があるそうです。
試験内容のリニューアル
以下は更新プログラムの話ではなく、新規に Azure Solutions Architect Expert の取得を目指している方向けの情報になります。
資格更新後にダッシュボードを見て気付いたのですが、資格の取得履歴・有効期限が 2 つのレコードで記載されています。
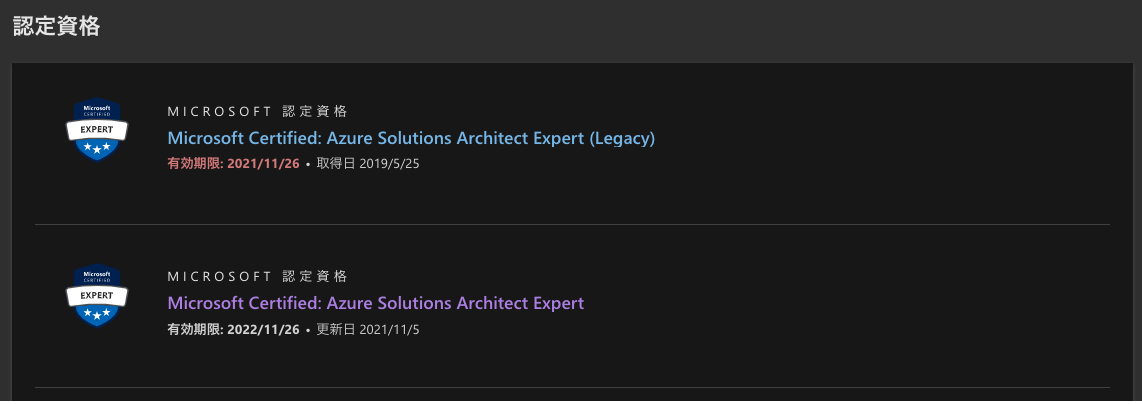
Azure Solutions Architect Expert はちょうど試験内容のリニューアルを行っている時期だったようで、資格の概要ページにアクセスしたところ、以下のように記載されていました。

資格の概要ページにもリンクがありますが、Microsoft Learn の Blog に詳しいスケジュールが載っていました。
2021 年 10 月 7 日に投稿されたこのブログ記事では、以下のスケジュールで認定試験がリニューアルされるとアナウンスされています。
- 2021 年 11 月 16 日から新試験の AZ-305 がベータ版で受験可能となる
- 2022 年 3 月 31 日をもって AZ-303, AZ-304 が廃止される
現在の試験要項に沿って AZ-303, AZ-304 向けの試験対策をされている方、すでにどちらかの試験をパスしている方などは、既存試験の受験時期に注意して早めに受験されることをおすすめします。
なお、リニューアル版の Azure Solutions Architect Expert の資格概要ページは以下の URL となっています。
https://docs.microsoft.com/en-us/learn/certifications/azure-solutions-architect/renew/
おわりに
これから更新プログラムの受験を予定されている方や、新たに Azure Solutions Architect Expert の取得を目指している方のお役に立てば幸いです。