2023 年の GKE の進化を振り返る
Google Cloud Champion Innovators Advent Calendar 2023 の 4 日目の記事です。
今年も GKE (Google Kubernetes Engine) には多くのアップデートがありました。
網羅的にアップデート情報を把握したい場合は GKE のリリースノート を見て頂ければと思いますが、定期的なバージョンアップデートの情報なども含むため、それなりのボリュームになっています。
そこで、この記事では「最近の GKE を追っていないので直近どのようなアップデートがあったのかざっくり把握したい」という方向けに、今年の GKE の主なアップデートを振り返り、自身の利用経験・知見と併せてご紹介したいと思います。
ちなみに、個人的なベストアップデートは「複数のノードプールの変更操作が並行して実行可能になったこと」です。
なお、GKE Standard / Autopilot のどちらか一方にのみ関連するアップデートについては、(Standard) または (Autopilot) という表記で運用モードを明記しています。
GKE Enterprise の登場から、従来の GKE を(運用モードとは関係なく) GKE Standard エディションと呼ぶようになったことでエディションと運用モードを誤解されるケースがありますが、この記事では特に明記しない限りエディションに関係なく利用可能なアップデートとお考えください。
ストレージ関連
(Standard) ローカル NVMe SSD がエフェメラルストレージとして利用可能に (2023/1)
NVMe を使ったローカル SSD を GKE ノードにプロビジョニングし、ワークロードのエフェメラルストレージとして利用できるようになりました。
永続化する必要のない中間ファイルの作成・読み取りなどを行う際にパフォーマンスの向上が期待できます。
ローカル SSD をアタッチする場合、GKE ノードに N1 や N2 といった第 1/2 世代のマシンシリーズを利用予定であれば、クラスタ作成時にオプションが必要となる点に注意しましょう(C3 のように第 3 世代のマシンシリーズの場合はオプション指定不要)。
また、デフォルトのマシンタイプである e2-medium はそもそも対応していない点にも注意です。
https://cloud.google.com/kubernetes-engine/docs/how-to/persistent-volumes/local-ssd
GKE 向けのマネージド Cloud Storage FUSE CSI ドライバが登場 (2023/5)
マネージド Cloud Storage FUSE CSI ドライバを用いて、Cloud Storage バケットをファイル システムとしてマウントできるようになりました。
エフェメラルストレージとして Cloud Storage バケットを指定するか、Cloud Storage バケットを参照する PersistentVolume リソースを作成することで利用可能となります。
5 月の時点ではプレビュー機能として登場していましたが、現在は GA しています。
GKE における Hyperdisk の利用が GA に (2023/6)
Persistent Disk の選択肢として Hyperdisk Throughput ボリュームと Hyperdisk Extreme ボリュームが加わり、いずれも GA で利用可能になりました。
Hyperdisk Throughput は Autopilot, Standard のどちらでも利用可能、更に高い IOPS を求めるワークロード用に用意された Hyperdisk Extreme は GKE Standard でのみ利用可能となっています。
一時ファイルへの頻繁な読み書きのあるワークロードなどでは Persistent Disk の IOPS が性能のボトルネックになることもあるため、こうしたケースに対する有力な選択肢が増えたのは嬉しいですね。
https://cloud.google.com/kubernetes-engine/docs/concepts/hyperdisk
スケーリング関連
(Autopilot) GKE Autopilot に Balanced コンピューティングクラスが登場 (2023/1)
2022 年後半から Autopilot ではワークロードの特性に応じてコンピューティングクラスを選択するということが可能になっていましたが、その選択肢に Balanced というクラスが追加されました。
Scale-Out のコンピューティングクラスには適さない、比較的少数で大きめのワークロードを実行する場合などに利用機会があるのではと思います。
デフォルトの 汎用(General-purpose)ではバースト可能な E2 マシンシリーズが利用されるため、急速に負荷の上昇するワークロードなどでは性能が安定しないケースがありましたが、Balanced ではクラスタ内のノードに 最小 CPU プラットフォーム の条件を満たすノードだけを割り当てる、といったことが可能になり、高負荷なワークロードに適したノードをある程度選択的に利用する事ができるようになりました。
https://cloud.google.com/kubernetes-engine/docs/concepts/autopilot-compute-classes
(Standard) クラスタオートスケーラーがスケールダウン時に複数ノードの Pod を同時並行で Drain 可能に (2023/3)
クラスタオートスケーラーがスケールダウンを判断してノードを終了させる際、複数のノードで同時並行的に Pod の Drain を行うことができるようになり、従来よりも素早く目標のサイズへスケールダウンできるようになりました。
一見地味なアップデートですが、ノードの増減が頻繁に起きる環境ではノードプールの調整待ちの時間が短くなり、コスト面でもメリットのあるアップデートでした。
https://cloud.google.com/kubernetes-engine/docs/concepts/cluster-autoscaler
(Autopilot) DaemonSet 利用時のノードサイズの自動最適化が登場 (2023/11)
Autopilot はノードの運用管理が不要にも関わらず DaemonSet が利用できるのですが、デプロイ順序を調整したり、事前に DaemonoSet に高めの PriorityClass を設定しておくなど、適切に全ノードにデプロイするためにはちょっとしたテクニックが必要となっていました。
これは、従来、DaemonSet を追加またはサイズ変更した場合、クラスタに追加済みのノードが必要リソースに足りない状況であっても既存ノードの再調整を行うことがなかったためです。
今回のアップデートでは、Autopilot がすべての DaemonSet のリソース要求に適合しないノードを自動検出し、要求に適合できるより大きなノードに自動移行できるようになりました。
ネットワーク関連
Cloud DNS for GKE でスタブドメイン等が利用可能に (2023/1)
GKE では従来、DNS プロバイダとして kube-dns が利用されてきましたが、その代替として最近は Cloud DNS for GKE が登場しています。
有効化すると、Pod や Service の DNS レコードが Cloud DNS に 自動的に登録され、クラスタ内の名前解決などを Cloud DNS によって処理することが可能になります。
このアップデートでは、Cloud DNS for GKE において IPv6 (シングル/デュアルスタック)や、スタブドメイン、アップストリームネームサーバとしての利用が可能になりました。
スタブドメイン等の利用により名前解決のリクエストを転送する場合は、以下の 2 点に注意しましょう。
Cloud DNS for GKE を利用する場合、kube-dns ConfigMap に設定した
stubDomainsとupstreamNameserversに基づくカスタム DNS 構成は、クラスタ内のノードと Pod の両方に適用されます。kube-dns を利用する場合は Pod にのみ適用されるため、ノードの名前解決の挙動に違いがあります。Cloud DNS for GKE を利用する場合、名前解決リクエストの転送元 IP アドレスは Cloud DNS のサービスが持つ IP アドレス範囲のいずれかとなります。一方、kube-dns を利用している場合は(VPC ネイティブクラスタであれば)Pod の IP アドレスが転送元となります。IP アドレス制限などの制約によって名前解決リクエストのソース IP アドレスが VPC の GKE ノード用 IP アドレス範囲でなければならない場合などには注意が必要です。
https://cloud.google.com/kubernetes-engine/docs/how-to/cloud-dns
バックエンドサービスベースの外部ネットワーク ロードバランサの GKE での利用が GA に (2023/3)
外部パススルーネットワークロードバランサ (External Regional L4 LB) を作成する際に、バックエンドサービスベースの構成が選択可能になりました。
従来のターゲットプールベースの外部パススルーネットワークロードバランサと比較すると、TCP, UDP 以外のプロトコルのトラフィックを負荷分散したり、コネクションドレイン が利用できるようになったりします。
https://cloud.google.com/load-balancing/docs/network#architecture
GKE Gateway Controller がグローバル外部 HTTP(S) ロード バランサで利用可能に (2023/4)
GKE Gateway Controller が External Global L7 LB でも利用可能なったことで、本格的に Kubernetes Gateway API に基づくロールベースのロードバランサ作成・運用が可能になりました(一応、Internal L7 LB は 2022/11 頃に先行して利用可能になっていました)。
従来の GKE Ingress Controller はユーザの各クラスタのコントロールプレーンに展開されていましたが、GKE Gateway Controller はユーザのクラスタやプロジェクトに依存せず、GKE クラスタの Kubernetes Gateway API へのリクエストに応じて適切なリソースを割り当て・管理するという、より抽象化された API サービスのようなアーキテクチャとなっています。
このアップデートのあとも、直近 1 年をかけて様々な GatewayClass のサポートが発表され、現在では複数のクラスタをバックエンドに持つマルチクラスタゲートウェイなども GA となっています。
GKE で利用可能な GatewayClass リソースについては こちら にまとまっています。
https://cloud.google.com/kubernetes-engine/docs/concepts/gateway-api#gateway_controller
(Standard) Pod 用のセカンダリ IP アドレス範囲を追加可能に (2023/5)
従来、ひとつのクラスタに対する Pod 用の IP アドレス範囲は連続するひとつのアドレス範囲を指定する必要があり、クラスタの作成後にアドレス範囲を変更・追加することはできませんでした。
このアップデートの登場により、既存のクラスタで Pod 用のセカンダリ IP アドレス範囲に不足が生じた場合に後から IP アドレス範囲を追加する、といった対応が可能になりました。
クラスタの IP アドレス設計の前提が変わるため、今後はより自由度の高い設計が行えそうですね。
https://cloud.google.com/kubernetes-engine/docs/how-to/multi-pod-cidr
1.27 以降の GKE で Konnectivity サービスが利用されるように (2023/5)
VPC ピアリングベースで構成されている限定公開クラスタは、GKE 1.27 以降、kube-apiserver からノードへのトラフィックに Konnectivity サービスを経由するようになりました。
Konnectivity サービスの仕組みや、GKE における仕様などについては以前調査して記事を書いていますのでご興味あればご参照ください。
https://polar3130.hatenablog.com/entry/2023/05/26/173000
GKE で FQDN ベースの Network Policy が利用可能に (2023/6)
FQDN (および正規表現) を使った下り方向 (クラスタ内のワークロードからクラスタ外へ) のネットワーク ポリシーが利用できるようになりました。
Cilium ベースのネットワーク制御の仕組みである Dataplane V2 を有効化した GKE で利用可能となっています。
FQDN Network Policy の仕様や、実機検証の様子について以前記事を書いていますのでご興味あればご参照ください。
https://polar3130.hatenablog.com/entry/2023/06/29/085200
(Standard) Pod のマルチネットワークサポートが登場 (2023/8)
こちらのアップデートにより、GKE 上で展開される Pod に複数のネットワークインタフェースをアタッチできるようになりました。
この機能は、GKE Dataplane V2 で使用されている eBPF の技術をもとに実装されています。
どうしても複数のネットワークに所属しなければならないワークロードがある、といったケースに答えられる選択肢ができたのは喜ばしいですね。
ネットワーク構成が複雑化するため、それこそ可視化ツールの恩恵に預かれると良いのですが、(現状はプレビューの機能ゆえか) モニタリング関連で紹介しているマネージド Hubble (GKE Dataplane V2 のオブザーバビリティ機能のひとつ) と併用できない点に注意が必要です。
この機能を利用することでクラスタやノードのスケーリングに関しては各種制限が追加されるため、利用を検討する場合は制限事項にもよく目を通しておくことをおすすめします。
https://cloud.google.com/kubernetes-engine/docs/how-to/setup-multinetwork-support-for-pods
モニタリング関連
(Standard) Managed Service for Prometheus が新規 Standard クラスタにおいてデフォルトで有効に (2023/6)
Managed Service for Prometheus が GKE 1.27 以降の新規 Standard クラスタにおいてデフォルトで有効化される仕様になりました。
GKE の新機能ではよくあることですが、既存ワークロードへの影響を最小限に留めるためか、既存クラスタを過去のバージョンからアップグレードして該当バージョンに引き上げた場合にはこうした機能は有効化されないことが多いです(今回もそうですね)。
既存クラスタで Managed Service for Prometheus を後から有効にしたい場合は明示的に有効化する必要があります。
https://cloud.google.com/stackdriver/docs/managed-prometheus/setup-managed#enable-mgdcoll-gke
GKE Dataplane V2 のオブザーバビリティ機能が利用可能に
GKE Dataplane V2 のメトリクス収集と、可視化ツールである Hubble の利用が可能になりました。
Hubble は Cilium と eBPF に基づくネットワークモニタリングと可視化のためのオープンソースツールで、Kubernetes クラスタ内の Hubble フローイベントと呼ばれるワークロード間の通信イベントをカウントし、相互に通信している Pod を特定・可視化するといった事が可能になっています。
オープンソースの Hubble プロジェクトはまだ GA (バージョン 1.0) には到達していないものの、現在活発に開発が進められており、個人的に今後の進展に注目しています。
https://cloud.google.com/kubernetes-engine/docs/concepts/about-dpv2-observability
https://github.com/cilium/hubble
(Autopilot) Autopilot で Kubernetes コントロールプレーンのログとメトリクスが収集可能に (2023/7)
Autopilot でも Kubernetes API Server, Scheduler, Controller Manager によって生成されたログとメトリクスを Cloud Logging と Cloud Monitoring にエクスポートできるようになりました。
トラブルシューティングの際にコントロールプレーンのログやメトリクスが解析の助けになることがあるため、Autopilot にも是非欲しいと思っていた嬉しいアップデートでした。
https://cloud.google.com/kubernetes-engine/docs/how-to/configure-metrics#control-plane-metrics
https://cloud.google.com/kubernetes-engine/docs/how-to/view-logs#control_plane_logs
セキュリティ関連
(Autopilot) Autopilot で CAP_NET_ADMIN が利用可能に (2023/6)
GKE Autopilot で CAP_NET_ADMIN の Linux Capability が利用可能になりました。 これにより、NET_ADMIN の権限を必要とする Istio や LinkerD などのサービスメッシュをユーザが Autopilot のクラスタに展開可能になりました。
余談ですが、Autopilot では Standard と比べてノードの管理がマネージドになっているぶん、セキュリティ機能の利用に制限(Standard との差分)があります。
Autopilot のセキュリティ機能の利用可否や制限については以下の公式ドキュメントにまとまっており、各種セキュリティ機能の利用可否などで迷った場合にはよくお世話になっています。
GKE Security Posture ダッシュボードが Cloud コンソールに登場 (2023/7)
GKE 関連のセキュリティ強化に役立つ、GKE Security Posture ダッシュボードという機能が新たに GA しました。
何故か GKE のリリースノートには載っていないアップデートなのですが、GKE クラスタとクラスタ上に展開されたワークロード構成を自動的にスキャンし、様々な観点で評価結果をダッシュボードに可視化してくれる機能となっています。
GA 直後の頃に実際に操作して使い勝手などをレポートした記事を書いていますので、ご興味があればこちらもご参照ください。
https://polar3130.hatenablog.com/entry/2023/07/04/180900
ML 関連
(Autopilot) Autopilot で GPU ワークロードの利用が GA に (2023/1)
今年最初の GKE のアップデートとして、Autopilot で GPU ワークロードの利用が GA となりました。
Pod のマニフェストに nodeSelector で cloud.google.com/gke-accelerator ラベルに必要な GPU タイプを指定することで、そのリクエストに応じた GPU ノードを Autopilot がプロビジョニングしてくれます。
Autopilot なので Pod 単位の課金がイメージされますが、リクエストした GPU タイプによっては、ノードにアタッチされたローカル SSD のコストが固定料金で発生する点に注意です(現状、NVIDIA A100 80GB のみが課金対象で、NVIDIA A100 40GB ではこの課金が発生しないようです)。
https://cloud.google.com/kubernetes-engine/docs/how-to/autopilot-gpus
(Standard) TPU ノードが利用可能に (2023/8)
GKE Standard で TPU が利用可能になり、TPU ノードで実行されているコンテナから出力されたログの収集や、TPU の使用状況に関するメトリクスの収集にも対応するようになりました。
その後のアップデートで 2023 年 11 月には Cloud TPU v5e マシンタイプも利用可能となっています。
デフォルトでは、TPU ノードに google.com/tpu の taint が設定されるため、TPU を利用しない Pod がスケジュールされないようになっています。
そのため、システム系 Pod を展開するために別途 TPU ノード以外のノードプールを用意しておく必要がある点に注意しましょう。
https://cloud.google.com/kubernetes-engine/docs/concepts/tpus
アップグレード関連
フリートまたはスコープによる、クラスタアップグレードの順序制御が可能に (2023/8)
Anthos やそれを包含する新しいエディションである GKE Enterprise など、フリートの概念で複数の GKE クラスタをグルーピングしている状況下において、フリートまたはスコープの単位でクラスタアップグレードのロールアウトの順序制御が行えるようになりました。
例えば、開発用のクラスタが含まれるフリートのクラスタをアップグレードしてから本番用のクラスタが含まれるフリートのアップグレードが行われるように定義することで、各クラスタが自動アップグレードを有効にしている場合でも必ず開発環境のクラスタを先にアップグレードする、といったことが可能になりました。
なお、このロールアウトの順序制御によって各クラスタのアップグレードを行った際、各クラスタのアップグレード後のバージョンが一致するのはマイナーバージョンの粒度までとなります。
各種セキュリティパッチ等のリリースによってパッチバージョンや GKE としてのリリースチャネルに設定されるデフォルトのリビジョンは随時変更されるため、全クラスタのロールアウト後にリビジョンの粒度では各クラスタのバージョンが一致しない点を理解して使用する必要があります。
https://cloud.google.com/kubernetes-engine/docs/concepts/about-rollout-sequencing
(Standard) 任意のクラスタにおいて、複数のノードプールの変更操作が並行して実行可能に (2023/8)
複数ノードプールの同時アップグレードや、ノードプールのアップグレード中に別のノードプールのサイズを変更するといった並行操作が可能になりました。
従来、ノードの追加やアップグレードなど、ノードプールの変更操作を行う場合、同時にはクラスタ内のいずれかひとつのノードプールのみでしか行うことができませんでしたが、このアップデートによって複数のノードプールを抱えるクラスタで柔軟な運用が行えるようになりました。
実際に複数のノードプールを同時に操作した時の様子や、使用上の制約等について調査した内容を以前記事にしていますので、ご興味があればこちらもご参照ください。
https://polar3130.hatenablog.com/entry/2023/08/31/200000
クラスタのルート CA の自動ローテーションポリシが導入される (2023/9)
GKE のクラスタルート CA は 5 年が有効期限 となっているため、CA の有効期限が切れる前にローテーションを行う必要があります(実質的にクラスタの再作成)。
そのため、特定のクラスタを継続的にアップグレードし続けて運用している場合などでは、5 年を目処に手動でローテーションの作業が必要となります。
今回新たに導入された自動化ポリシーでは、ルート CA の有効期限が切れるまで 30 日を切ると、GKE が自動的にこのローテーションを試みます。
この自動ローテーションはクラスタに設定しているメンテナンス除外の設定を無視して実行されます。
ローテーションはノードや Pod の再作成、クラスタ API の一時停止などを伴うため、(公式ドキュメントにも記載されていますが) 最終手段となるこの自動化ポリシーに頼るのではなく、事前にユーザが手動で計画的にローテーションを行うようにしましょう。
https://cloud.google.com/kubernetes-engine/docs/how-to/credential-rotation
その他
GKE 1.26 以降で cgroup v2 がコンテナリソース管理のデフォルトに (2023/1)
他のアップデートと比べて少し低レイヤの話になりますが、Linux カーネルのリソース制御の仕組みである cgroup のバージョンが上がり、1.26 以降のバージョンで作成された新しいノードプールは cgroup v2 がデフォルトで利用されるようになりました。
cgroup v2 詳しくは下記の Kubernetes 公式ドキュメントや、技術評論社さんの記事をご覧頂くと良いかと思います。
Kubernetes としては v1.25 以降で cgroup v2 の利用が Stable となっており、メモリ QoS のように cgroup v2 でなければ利用できない機能もあります。
https://kubernetes.io/docs/concepts/architecture/cgroups/
https://gihyo.jp/admin/serial/01/linux_containers/0045
Kubernetes のイメージレジストリが k8s.gcr.io から registry.k8s.io に変更 (2023/3)
オープンソースの Kubernetes のアップデートではありますが、GKE ユーザにも影響を受けたアップデートで、GKE のリリースノートにも当時掲載されていました。
エンタープライズではアクセス可能なレジストリが制限されているケースも少なくないと思いますので、こうしたアップストリームの変更も追いかけておくとインシデントを未然に防ぐことにつながるかと思います。
https://kubernetes.io/blog/2023/03/10/image-registry-redirect/
GKE Enterprise の登場 (2023/8)
今年の GKE で特に大々的にアナウンスされたリリースとしては、Google Cloud Next '23 で登場したこちらの GKE Enterprise が挙げられるのではないでしょうか。
マルチクラスタ構成で役立つ Ingress や、クラスタのマルチテナント利用に適したチーム管理機能など、大規模に GKE を利用するエンタープライズユーザ向けの機能を持つ GKE となっています。
私個人としては Anthos のリブランディングに近いイメージを持っています。
GKE Enterprise が登場した背景や、目指している世界観、提供される主な機能などについては、下記のウェビナーで紹介されていますのでこちらも併せてご確認頂くと良いかと思います。
各エディションの持つ機能の違いについては、公式ドキュメントの こちら を参照ください。
ちなみに、GKE にエディションのような概念が設けられたのはこれが初めてではありません。
かつて Next '19 ではエンタープライズ向けの GKE として GKE Advanced が発表されており、このときにも従来の GKE を GKE Standard と呼称していました。
その後、GKE Advanced は Next '18 で先に発表されていた Cloud Services Platform とともに、Anthos に統合され、今回はその Anthos が GKE Enterprise の中に包含された、というような経緯と理解しています。
おわりに
2023 年の GKE の進化をざっと振り返ってみました。
なお、それぞれのアップデートは利用可能となる GKE のバージョンが決まっていますので、アップデートされた機能の利用を検討する際は最低利用可能バージョンを公式ドキュメントでご確認ください。
紹介しきれなかったアップデートもたくさんありますので、気になった方はぜひ GKE のリリースノートも覗いてみて頂くと良いかと思います。
来年はどのようなアップデートがあるのか、今から楽しみです。
Calico から GKE Dataplane V2 への移行を考える
Google Cloud の GKE (Google Kubernetes Engine) では、Calico と Dataplane V2 という 2 つのネットワーク制御の仕組みが提供されています。
どちらも Kubernetes NetworkPolicy を利用できるようになっていますが、Calico は iptables を利用してルーティングを制御する一方、Dataplane V2 は Cilium をベースとして eBPF によってルーティングを制御します。
今回は、Calico から GKE Dataplane V2 への移行を考えるにあたって、NetworkPolicy 関連で検証したことの一部をご紹介します。
GKE Dataplane V2 とは
GKE Dataplane V2 (以降、Dataplane V2) は Cilium をベースとした GKE のネットワーク制御の仕組みで、2020年8月に発表されました。※1
kube-proxy や iptables に依存しなくなることでネットワーク制御のパフォーマンス向上が期待できるほか、ネットワークポリシーロギング の機能によって NetworkPolicy の適用結果 (Allow / Deny) をログに出力する機能を備えるなど、従来の Calico CNI に基づくネットワーク制御では得られなかった複数のメリットがあります。
現時点では、Calico を用いた既存のネットワーク制御の仕組みを完全に置き換えるものではない(並行して提供されている)ため、Standard クラスタであればユーザがどちらかを選択して利用することになります(Autopilot では Dataplane V2 が採用されており、これを変更することはできません)。
なお、現時点では既存の GKE Standard クラスタを Calico から Dataplane V2 に移行する手段は提供されていないため、移行する場合は新規にクラスタを作成する必要があります。
Dataplane V2 は Cilium をベースとしているものの、あくまで Google 独自の実装であり、Cilium と完全な互換性があるものではありません。
例えば、Cilium では Kubernetes NetworkPolicy のほかに、拡張された NetworkPolicy である CiliumNetworkPolicy や CiliumClusterwideNetworkPolicy を併用することができますが、現在の GKE (1.21.5-gke.1300 以降) ではこれらの Cilium CRD はサポートされていません。※2
機能によっては Dataplane V2 側に代替実装が用意されている場合もあります。
例えば、L7 の FQDN に基づく NetworkPolicy を定義したい場合、Cilium であれば CiliumNetworkPolicy がその役割を担っていますが、Dataplane V2 の場合は FQDNNetworkPolicy が同様の目的を果たす手段として用意されています(FQDNNetworkPolicy については以前検証したブログ記事がありますので、ご興味があれば こちら も併せてどうぞ)。
なお、両者は YAML の書き方が異なり、機能にも差分があるため、同じものとして扱うことはできません。
※1 余談も余談ですが、Google Cloud には GKE Dataplane V2 と名前の似た Cloud Interconnect Dataplane V2 というものがありますが、これらは単純に第二世代という意味であり、実装に強い関連性を持っているわけではありません。例えば、Cloud Interconnect Dataplane V2 は Cilium や eBPF の技術とは無関係(のはず)です。
※2 "GKE バージョン 1.21.5-gke.1300 以降、GKE Dataplane V2 は CiliumNetworkPolicy または CiliumClusterwideNetworkPolicy CRD API をサポートしていません。" (Dataplane V2 の 制限事項 より)
今回の検証ポイントと背景
Calico から Dataplane V2 に安全に移行するためには、様々な観点で検証が必要になると考えられます。
今回は、Calico と Dataplane V2 の Kubernetes NetworkPolicy に関する機能差分に着目し、Dataplane V2 では無効となる構成を実際に Apply してみた場合の挙動を調べてみました。
GKE のこちらの 公式ドキュメント によると、Dataplane V2 では、NetworkPolicy を定義する際に以下のような制約があることがわかります。
これらの制約に該当する構成は、「無効」になると記載されています。
- ipBlock.cidr フィールドに Pod または Service の IP アドレスを使用することはできない(代わりに、ラベルを指定して対象のワークロードを特定する必要がある)
- 空の ports.port フィールドを指定することはできない(ポートを指定する際は必ずプロトコルも指定する必要がある)
Calico からの移行という前提に立つと、大量に存在する NetworkPolicy の中に上記制約に該当するものが混在しており、NetworkPolicy マニフェストの単純な移行を試みて無効な構成を Apply しようとしてしまう、といった可能性は考えられそうです。
上記制約の個々は決して深刻なものではありませんが、これが全てとは限らず、今後 Calico の発展や Dataplane V2 としての実装の都合上などにより他にも Calico との違いが生まれてくる可能性が考えられます。
そうした場合に、構成が「無効」になる、とは具体的にはどういった挙動を示すのでしょうか。
「無効」な構成の NetworkPolicy マニフェストを Apply すると Dataplane V2 はどうなるのか、そもそも Apply できるのか、といった挙動を確認してみようというのが今回の主旨です。
※ ちなみに、上記の制約は Cilium の 公式ドキュメント でも Cilium の Kubernetes NetworkPolicy における Known Issue として紹介されているため、Dataplane V2 独自の制約というわけではなさそうです
実機検証
それでは実際に GKE Standard のクラスタを用意して検証してみましょう。
今回は以下のとおり、Dataplane V2 を有効化した GKE 1.27.3-gke.100 のクラスタを用意しました。
$ gcloud container clusters describe sample-cluster
addonsConfig:
dnsCacheConfig:
enabled: true
networkPolicyConfig:
disabled: true
...
autopilot: {}
clusterIpv4Cidr: 10.32.0.0/14
currentMasterVersion: 1.27.3-gke.100
currentNodeCount: 3
currentNodeVersion: 1.27.3-gke.100
ipAllocationPolicy:
clusterIpv4Cidr: 10.32.0.0/14
clusterIpv4CidrBlock: 10.32.0.0/14
clusterSecondaryRangeName: gke-sample-cluster-pods-099d0671
servicesIpv4Cidr: 10.36.0.0/20
servicesIpv4CidrBlock: 10.36.0.0/20
servicesSecondaryRangeName: gke-sample-cluster-services-099d0671
stackType: IPV4
useIpAliases: true
...
location: us-central1
name: sample-cluster
network: default
networkConfig:
datapathProvider: ADVANCED_DATAPATH
defaultSnatStatus: {}
network: projects/****************/global/networks/default
serviceExternalIpsConfig: {}
subnetwork: projects/****************/regions/us-central1/subnetworks/default
...
nodeConfig:
machineType: e2-medium
...
Dataplane V2 という表記はありませんが、networkConfig.datapathProvider が ADVANCED_DATAPATH になっていることから、このクラスタで Dataplane V2 が有効化されていることがわかります(Calico CNI を利用する場合は networkConfig.datapathProvider が LEGACY_DATAPATH , networkPolicy.provider が CALICO になります)。
また、Dataplane V2 の場合は networkPolicy.provider のフィールドがそもそも存在しないようですが、これは Dataplane V2 の場合デフォルトで NetworkPolicy が有効化されている(Disable できない)ためと考えられます。
次に、NetworkPolicy の動作確認のため、適当な Pod を 3 つほどクラスタに展開します。
$ kubectl run pod1 --image nginx pod/pod1 created $ kubectl run pod2 --image nginx pod/pod2 created $ kubectl run pod3 --image nginx pod/pod3 created $ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod1 1/1 Running 0 16s 10.32.2.8 gke-sample-cluster-default-pool-c40d772e-l3kh <none> <none> pod2 1/1 Running 0 9s 10.32.2.9 gke-sample-cluster-default-pool-c40d772e-l3kh <none> <none> pod3 1/1 Running 0 5s 10.32.2.10 gke-sample-cluster-default-pool-c40d772e-l3kh <none> <none>
検証用の Kubernetes NetworkPolicy のマニフェストは以下を用意しました。
Dataplane V2 では「無効」な構成とされている、ipBlock.cidr フィールドに Pod の IP アドレスを使用したポリシとなっています。
今回は動作検証が目的であるためあえてこのようなポリシを作成していますが、一般的にはクラスタ内の Pod に対して ipBlock でポリシを作成するのはアンチパターンです。
Pod の IP アドレスは動的に付与され、稼働中に再スケジュールなどで変動する可能性があります。
$ cat testnetpol.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector: {}
policyTypes:
- Ingress
ingress:
- from:
- ipBlock:
cidr: 10.32.2.8/32
egress:
- {}
この無効なマニフェストをクラスタに Apply してみるとどうなるでしょうか。
$ kubectl apply -f testnetpol.yaml
apiVersion: networking.k8s.io/v1
networkpolicy.networking.k8s.io/test-network-policy created
$ kubectl describe networkpolicy test-network-policy
Name: test-network-policy
Namespace: default
Created on: 2023-09-23 14:20:57 +0000 UTC
Labels: <none>
Annotations: <none>
Spec:
PodSelector: <none> (Allowing the specific traffic to all pods in this namespace)
Allowing ingress traffic:
To Port: <any> (traffic allowed to all ports)
From:
IPBlock:
CIDR: 10.32.2.8/32
Except:
Not affecting egress traffic
Policy Types: Ingress
Apply することができました。
無効といえど、Apply の時点でバリデーションが行われるということではなさそうです。
次に、この NetworkPolicy がどのように動作するのかを見てみましょう。
今回のポリシは、Ingress を pod1 の IP アドレス(10.32.2.8/32)からのみ許可し、Egress に関しては関与しない(すべて許可)、という設定になっています。
従って、pod1 から他の Pod への通信は(このポリシが正常に機能すれば)許可されるはずです。
$ kubectl exec -it pod1 -- sh # curl 10.32.2.10 (タイムアウト) # exit command terminated with exit code 130 $ kubectl delete -f testnetpol.yaml networkpolicy.networking.k8s.io "test-network-policy" deleted $ kubectl exec -it pod1 -- sh # curl 10.32.2.10 ...(略)... Welcome to nginx! ...(略)...
結果、pod1 から pod3 (10.32.2.10) への curl は失敗となりました。
該当の NetworkPolicy を取り除くと、当然ながら pod1 から他の Pod へのリクエストは正常に到達可能になりました。
Dataplane V2 の場合は、ネットワークポリシーロギングを利用できるため、ログエントリからも動作の様子を確認してみましょう。
このクラスタの NetworkLogging の設定は以下のとおりです。
予め Allow / Deny のどちらの場合でも NetworkPolicy の動作に関するログが Cloud Logging に出力されるよう設定しています。
$ kubectl describe networklogging
Name: default
Namespace:
Labels: addonmanager.kubernetes.io/mode=EnsureExists
Annotations: components.gke.io/component-name: advanceddatapath
components.gke.io/component-version: 27.6.0
components.gke.io/layer: addon
API Version: networking.gke.io/v1alpha1
Kind: NetworkLogging
Metadata:
Creation Timestamp: 2023-09-22T15:19:29Z
Generation: 2
Resource Version: 778820
UID: 7df685fc-397d-4f43-9d81-ff88d6ad7863
Spec:
Cluster:
Allow:
Delegate: false
Log: true
Deny:
Delegate: false
Log: true
Events: <none>
出力されたログエントリを Cloud Logging から確認してみます。
上記の curl コマンドに対して、6 件のログエントリが生成されていました。

今回の場合は、定義したポリシが pod1 と pod3 の両方を対象とするため、pod1 から pod3 への curl リクエストは pod1 からの Egress と pod3 への Ingress の 2 つのタイミングで評価されていることがわかります。
1 件目のエントリでは、pod1 からの Egress トラフィックが許可されていることがわかります。
{
"insertId": "dhickie3cds9bxp7",
"jsonPayload": {
"dest": {
"pod_namespace": "default",
"namespace": "default",
"pod_name": "pod3"
},
"disposition": "allow",
"node_name": "gke-sample-cluster-default-pool-c40d772e-l3kh",
"count": 1,
"src": {
"namespace": "default",
"pod_namespace": "default",
"pod_name": "pod1"
},
"connection": {
"dest_ip": "10.32.2.10",
"protocol": "tcp",
"src_port": 48512,
"dest_port": 80,
"direction": "egress",
"src_ip": "10.32.2.8"
},
"policies": [
{
"kind": "NetworkPolicy",
"name": "test-network-policy",
"namespace": "default"
}
]
},
"resource": {
"type": "k8s_node",
"labels": {
"location": "us-central1",
"project_id": "****************",
"cluster_name": "sample-cluster",
"node_name": "gke-sample-cluster-default-pool-c40d772e-l3kh"
}
},
"timestamp": "2023-09-23T14:21:51.384375643Z",
"logName": "projects/****************/logs/policy-action",
"receiveTimestamp": "2023-09-23T14:21:54.247088734Z"
}
2 件目のエントリでは、pod3 への Ingress トラフィックが拒否されていることが確認できます。
3 件目以降のエントリは curl の再試行によるもので、2 件目とログの内容は同じです。
{
"insertId": "akf4ygd85sv6au09",
"jsonPayload": {
"disposition": "deny",
"node_name": "gke-sample-cluster-default-pool-c40d772e-l3kh",
"count": 3,
"src": {
"pod_name": "pod1",
"pod_namespace": "default",
"namespace": "default"
},
"dest": {
"pod_name": "pod3",
"namespace": "default",
"pod_namespace": "default"
},
"connection": {
"direction": "ingress",
"protocol": "tcp",
"dest_ip": "10.32.2.10",
"src_port": 48512,
"src_ip": "10.32.2.8",
"dest_port": 80
}
},
"resource": {
"type": "k8s_node",
"labels": {
"location": "us-central1",
"project_id": "****************",
"node_name": "gke-sample-cluster-default-pool-c40d772e-l3kh",
"cluster_name": "sample-cluster"
}
},
"timestamp": "2023-09-23T14:21:51.384394882Z",
"logName": "projects/****************/logs/policy-action",
"receiveTimestamp": "2023-09-23T14:21:59.247442915Z"
}
1 件目と 2 件目のエントリを見比べると、1 件目は評価した NetworkPolicy のリソース名 (test-network-policy) がログエントリに含まれているのに対し、2 件目には含まれていませんでした。
考察・検証から得られた気付き
Dataplane V2 における無効な NetworkPolicy がどのような影響を与えるのか、上記の検証を通じて得られたいくつかの気付きを共有します。
まず、無効なマニフェストであってもクラスタに Apply することは可能なようです。
無効なポリシの対象となったトラフィックはタイムアウトし、明示的なエラーは返却されません。
加えて、Calico CNI を利用したクラスタで利用している NetworkPolicy を単純移行しようとすると無効なポリシも含めて Apply には成功してしまいます。
そのため、場合によっては無効なポリシが悪影響を及ぼしていることに気付くのが遅れるといった可能性がありそうです。
今回は折角 Dataplane V2 を利用しているため、ネットワークポリシーロギングからも無効なポリシに関する挙動を確認しました。
ログエントリの内容にそれを判別できる特徴があるのであれば、NetworkPolicy が期待した動作をしない場合に無効な構成を Apply してしまっている可能性に気付けるきっかけにできます。
検証では、pod1 からの Egress の許可には評価した NetworkPolicy のリソース名が含まれ、pod3 への Ingress の拒否にはリソース名が含まれていなかったことから、ネットワークポリシが無効な設定の場合はログエントリにリソース名が表示されないのでは(無効なポリシなので、そもそも Ingress を正しく評価できる NetworkPolicy がいない → policies フィールドが空になる)と想定しました。
しかし、以下のように有効な構成と思われる AllDeny のポリシを Apply した場合であっても、Deny ログには policies フィールドが含まれていない(拒否の理由となった NetworkPolicy のリソース名はログエントリからわからない)ため、どうやら単純に拒否 (Deny) のログエントリは「拒否の理由が、正しく評価できる NetworkPolicy であるか、無効なポリシが Apply されているためかに関わらず、policies フィールドが含まれない」ようです。
そのため、ネットワークポリシーロギングのエントリから直接的に無効なポリシの存在に気付くのは難しそうですね。
$ cat alldeny.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
$ kubectl apply -f alldeny.yaml
networkpolicy.networking.k8s.io/default-deny-all created
$ kubectl get netpol
NAME POD-SELECTOR AGE
default-deny-all <none> 44m
$ kubectl exec pod1 -it -- sh
# curl 10.32.2.10
(タイムアウト)
# exit
command terminated with exit code 130
$ gcloud logging read 'insertId=o0qc79kobivrxvmm'
---
insertId: o0qc79kobivrxvmm
jsonPayload:
connection:
dest_ip: 10.32.2.10
dest_port: 80
direction: egress
protocol: tcp
src_ip: 10.32.2.8
src_port: 42996
count: 3
dest:
namespace: default
pod_name: pod3
pod_namespace: default
disposition: deny
node_name: gke-sample-cluster-default-pool-c40d772e-l3kh
src:
namespace: default
pod_name: pod1
pod_namespace: default
logName: projects/****************/logs/policy-action
receiveTimestamp: '2023-09-25T02:23:59.248034900Z'
resource:
labels:
cluster_name: sample-cluster
location: us-central1
node_name: gke-sample-cluster-default-pool-c40d772e-l3kh
project_id: ****************
type: k8s_node
timestamp: '2023-09-25T02:23:50.903492410Z'
以上より、Calico から Dataplane V2 への移行というシナリオにおいて、既存の NetworkPolicy をひとまず投入してから挙動やログに基づいて構成を修正してゆく、というアプローチはちょっと難しそうです。
移行にあたって無効なポリシを Apply してしまうリスクに対しては、Dataplane V2 や Cilium の Known Issue ・制限事項などに該当するマニフェストがないかなど、事前の精査にウェイトを置くほうが良さそうですね。
まとめ
Calico CNI から GKE Dataplane V2 への移行というシチュエーションをもとに、Dataplane V2 において無効な NetworkPolicy がどのような影響を与えるのかについて、実機検証を交えて調べました。
パフォーマンスや可観測性など、既存ワークロードの移行においては色々と検討すべき事項があるかと思いますが、そのひとつの観点として記事の情報が何かのお役に立てば幸いです。
GKE ノードプールの並行アップグレード
Google Cloud Next '23 、盛り上がっていますね!
AI / ML 系のアップデートが目玉となっていますが、その他のサービスでも数多くのアップデートがリリースされています。
本記事では、Google Cloud Next '23 の開催期間中に発表された GKE 関連のアップデートのなかでも個人的に注目の「ノードプールの並行アップグレード」をピックアップしてご紹介します。
リリースノートはこちら:
機能概要
GKE は、ひとつのクラスタにワークロードやインスタンスタイプに応じた複数のノードプールを設けることができます。
従来、GKE のアップグレードや自動プロビジョニングを行う場合は、いずれかのノードプールでアップグレードやプロビジョニングなどの構成変更が行われている間、他のノードプールやクラスタの設定を変更することができないという制約がありました。
今回のアップデートにより、GKE クラスタ内の複数のノードプールを並行してアップグレード・自動プロビジョニングすることができるようになったため、上記の運用上の制約が解消されました。
このアップデートに関して特定のドキュメントは設けられていないようですが、リリースノートによれば既に GKE のすべてのバージョンで利用可能となっているようです。
実機検証
早速、実機で並行アップグレードを試してみたいと思います。
どのバージョンでも利用可能とのことだったので、あえて最新ではない GKE 1.23 (1.23.17-gke.10700) のクラスタを用意しました。
ふたつのノードプール (pool-1, pool-2) も作成しておきます。
$ gcloud container clusters describe sample-cluster
...
currentMasterVersion: 1.23.17-gke.10700
currentNodeCount: 6
currentNodeVersion: 1.23.17-gke.10700
initialClusterVersion: 1.23.17-gke.10700
location: us-central1
locations:
- us-central1-a
- us-central1-c
- us-central1-f
name: sample-cluster
nodeConfig:
diskSizeGb: 50
diskType: pd-balanced
imageType: COS_CONTAINERD
machineType: e2-small
...
nodePoolAutoConfig: {}
nodePoolDefaults:
nodeConfigDefaults:
loggingConfig:
variantConfig:
variant: DEFAULT
nodePools:
- autoscaling: {}
config:
diskSizeGb: 50
diskType: pd-balanced
imageType: COS_CONTAINERD
machineType: e2-small
...
initialNodeCount: 1
locations:
- us-central1-a
- us-central1-c
- us-central1-f
management:
autoRepair: true
autoUpgrade: true
maxPodsConstraint:
maxPodsPerNode: '110'
name: pool-1
status: RUNNING
upgradeSettings:
maxSurge: 1
strategy: SURGE
version: 1.23.17-gke.10700
- autoscaling: {}
config:
diskSizeGb: 50
diskType: pd-balanced
imageType: COS_CONTAINERD
machineType: e2-small
...
initialNodeCount: 1
locations:
- us-central1-a
- us-central1-c
- us-central1-f
management:
autoRepair: true
autoUpgrade: true
maxPodsConstraint:
maxPodsPerNode: '110'
name: pool-2
status: RUNNING
upgradeSettings:
maxSurge: 1
strategy: SURGE
version: 1.23.17-gke.10700
releaseChannel: {}
status: RUNNING
zone: us-central1
ノードプールのアップグレードを検証するには、先にクラスタのコントロールプレーンのバージョンをアップグレードしておかなければなりません。
今回はまずコントロールプレーンを 1.24.16-gke.500 に手動アップグレードします。
$ gcloud container clusters upgrade sample-cluster --master --cluster-version 1.24.16-gke.500 Master of cluster [sample-cluster] will be upgraded from version [1.23.17-gke.10700] to version [1.24.16-gke.500]. This operation is long-running and will block other operations on the cluster (including delete) until it has run to completion. Do you want to continue (Y/n)? Y ...
アップグレードが開始されました。
コントロールプレーンのアップグレード中は、ユーザがクラスタの構成(ノードプールの追加や削除、既存ノードプールのサイズ変更、クラスタの削除など)が一切行えません。
コンソールで確認すると以下のような表示となっており、クラスタやノードプールの設定を変更するボタンが押せなくなっていることがわかります(API でリクエストしてもエラーが返却されます)。

コントロールプレーンのアップグレードが完了したら、次は pool-1 のアップグレードに進みます。 こちらも 1.24.16-gke.500 に手動アップグレードします。
$ gcloud container clusters list NAME: sample-cluster LOCATION: us-central1 MASTER_VERSION: 1.24.16-gke.500 MASTER_IP: 34.132.4.227 MACHINE_TYPE: e2-small NODE_VERSION: 1.23.17-gke.10700 * NUM_NODES: 6 STATUS: RUNNING * - There is an upgrade available for your cluster(s). To upgrade nodes to the latest available version, run $ gcloud container clusters upgrade NAME $ gcloud container clusters upgrade sample-cluster --node-pool=pool-1 --cluster-version 1.24.16-gke.500 All nodes in node pool [pool-1] of cluster [sample-cluster] will be upgraded from version [1.23.17-gke.10700] to version [1.24.16-gke.500]. This operation is long-running and will block other operations on the cluster (including delete) until it has run to completion. Do you want to continue (Y/n)? Y Upgrading sample-cluster...Updating pool-1, done with 0 out of 3 nodes (0.0%): 1 being processed...working..
アップグレードが開始されました。
従来であれば、ノードプールのアップグレード中においても、コントロールプレーンのアップグレードと同様に、いずれかのノードプールでアップグレードが行われている最中は別のノードプールの構成を変更することができませんでした。
それではここで、pool-1 のアップグレードの最中ですが pool-2 のアップグレードもリクエストしてみましょう。
$ gcloud container clusters upgrade sample-cluster --node-pool=pool-2 --cluster-version 1.24.16-gke.500 All nodes in node pool [pool-2] of cluster [sample-cluster] will be upgraded from version [1.23.17-gke.10700] to version [1.24.16-gke.500]. This operation is long-running and will block other operations on the cluster (including delete) until it has run to completion. Do you want to continue (Y/n)? Y Upgrading sample-cluster... Updating pool-2, done with 0 out of 3 nodes (0.0%): 1 being processed...working..
pool-1 のアップグレード実行中に、pool-2 も並行してアップグレードを開始することができました。
コンソールでは以下のような表示になっていました。
「ノードプールを追加」のボタンは依然としてグレーアウトされているため、コンソールでの操作にはまだ対応していないようですが、同時に複数のノードプールのアップグレードが進行していることがわかります。

ちなみにプログレスバーが 2 本表示されていますが、これだけではどちらのバーがどちらのノードプールを指しているのか一見わからない表示となっています。
見た目の問題ではありますが、今後の改善に期待したいですね。
追加検証
ここからは、他のパターンでも複数のノードプールの構成変更が並行できるのかを試してみたいと思います。
まずは、pool-1 と pool-2 の同時アップグレード中に、pool-2 のアップグレードを中断してみましょう。
ノードプールのアップグレードを中断するには、クラスタに対するオペレーション ID を取得し、gcloud container operations cancel コマンドを実行します。
なお、ノードプールのアップグレードの中断を行うと、アップグレード未了のノードは古いバージョンのままとなりますが、アップグレードが完了しているノードはロールバックされず、先のオペレーションでアップグレードされたバージョンのままとなります。
$ gcloud container operations list
NAME: operation-1693444380760-f5e0b489-04d0-495d-9f8a-ba613bc87bdb
TYPE: CREATE_CLUSTER
LOCATION: us-central1
TARGET: sample-cluster
STATUS_MESSAGE:
STATUS: DONE
START_TIME: 2023-08-31T09:13:00.760134453Z
END_TIME: 2023-08-31T09:17:42.6150337Z
NAME: operation-1693446415977-691a9f00-3221-4e62-ab01-16731084b815
TYPE: UPGRADE_MASTER
LOCATION: us-central1
TARGET: sample-cluster
STATUS_MESSAGE:
STATUS: DONE
START_TIME: 2023-08-31T09:46:55.977872348Z
END_TIME: 2023-08-31T10:13:50.711133596Z
NAME: operation-1693448209722-720779cc-1896-4ffa-b956-3f9bc38581d2
TYPE: UPGRADE_NODES
LOCATION: us-central1
TARGET: pool-1
STATUS_MESSAGE:
STATUS: RUNNING
START_TIME: 2023-08-31T10:16:49.722711057Z
END_TIME:
NAME: operation-1693448391857-34fcdbe6-faed-4512-b636-1577dd989f0b
TYPE: UPGRADE_NODES
LOCATION: us-central1
TARGET: pool-2
STATUS_MESSAGE:
STATUS: RUNNING
START_TIME: 2023-08-31T10:19:51.857597571Z
END_TIME:
$ gcloud container operations cancel operation-1693448391857-34fcdbe6-faed-4512-b636-1577dd989f0b
Are you sure you want to cancel operation operation-1693448391857-34fcdbe6-faed-4512-b636-1577dd989f0b?
Do you want to continue (Y/n)? Y
Cancelation of operation operation-1693448391857-34fcdbe6-faed-4512-b636-1577dd989f0b has been requested. Please use gcloud container operations describe operation-1693448391857-34fcdbe6-faed-4512-b636-1577dd989f0b to check if the operation has been canceled successfully.
detail: 'Updating pool-2, done with 2 out of 3 nodes (66.7%): 1 being processed'
name: operation-1693448391857-34fcdbe6-faed-4512-b636-1577dd989f0b
operationType: UPGRADE_NODES
progress:
metrics:
- intValue: '3'
name: NODES_TOTAL
- intValue: '0'
name: NODES_FAILED
- intValue: '2'
name: NODES_COMPLETE
- intValue: '2'
name: NODES_DONE
- intValue: '0'
name: NODE_PDB_DELAY_SECONDS
selfLink: https://container.googleapis.com/v1/projects/950837876919/locations/us-central1/operations/operation-1693448391857-34fcdbe6-faed-4512-b636-1577dd989f0b
startTime: '2023-08-31T10:19:51.857597571Z'
status: ABORTING
targetLink: https://container.googleapis.com/v1/projects/950837876919/locations/us-central1/clusters/sample-cluster/nodePools/pool-2
zone: us-central1
引き続き pool-1 はアップグレード中ですが、pool-2 のアップグレードを中断させることができました。
次に、pool-1 がアップグレード中のまま、pool-2 アップグレードを再開してみます。
アップグレードを再開する場合は、通常のアップグレードと同じコマンドを再度実行するだけで再開できます。
$ gcloud container clusters upgrade sample-cluster --node-pool=pool-2 --cluster-version 1.24.16-gke.500 All nodes in node pool [pool-2] of cluster [sample-cluster] will be upgraded from version [1.24.16-gke.500] to version [1.24.16-gke.500]. This operation is long-running and will block other operations on the cluster (including delete) until it has run to completion. Do you want to continue (Y/n)? Y Upgrading sample-cluster... Updating pool-2, done with 2 out of 3 nodes (66.7%): 1 succeeded...done.
こちらも問題なくオペレーションできました。
pool-1 のアップグレードは完了しましたが、中断後に再開した pool-2 は引き続きアップグレードが進行中です。
そこで今度は、 pool-2 のアップグレード中に新しく pool-3 というノードプールを作成してみましょう。
$ gcloud beta container --project "hypnotic-surge-397600" node-pools create "pool-3" --cluster "sample-cluster" --region "us-central1" --node-version "1.24.16-gke.500" --machine-type "e2-small" --image-type "COS_CONTAINERD" --disk-type "pd-balanced" --disk-size "20" --metadata disable-legacy-endpoints=true --scopes ... Note: Node version is specified while node auto-upgrade is enabled. Node-pools created at the specified version will be auto-upgraded whenever auto-upgrade preconditions are met. Creating node pool pool-3...working..
こちらも問題なくオペレーションできました。
更に、pool-2 のアップグレード完了後、 pool-3 のアップグレード中に今度は pool-2 のスケールアウト(ノードプールのサイズ変更)を行ってみましょう。
$ gcloud container clusters resize sample-cluster --node-pool pool-2 --num-nodes 2 Pool [pool-2] for [sample-cluster] will be resized to 2 node(s) in each zone it spans. Do you want to continue (Y/n)? Y Resizing sample-cluster...working..
こちらも問題なくオペレーションできました。
コンソールからも、pool-2 のサイズ変更と pool-3 の新規作成が並行して実行できていることがわかります。

利用時の注意点
主なユースケースとしては、これまで直列に実行する必要のあった複数ノードプールのアップグレードの並行実施が考えられます。
アップグレード戦略によりますが、サージアップグレードの場合は最大サージ(max-surge-upgrade)とオフライン上限(max-unavailable-upgrade)の設定に注意しましょう。
並行で複数のノードプールのアップグレードを実行することで、あるタイミングで利用できないノードの数が直列で実施しているときよりも増えるため、クラスタ全体の利用可能リソースが少なくなり、最悪の場合古いノードを Evict しても新しいスケジュール先を確保できない、という状況に陥る可能性が出てくるかもしれません。
同時にアップグレードを行ってもクラスタのリソースの総量として問題がないかを事前に確認する、あるいはより安全なアップグレードを計画したい場合は Blue / Green によるアップグレード戦略を選択すると良いでしょう。
また、今回のアップデートによって、ノードプールのアップグレード中にトラブルが起きた場合の対応の選択肢が増えました(以前はアップグレード中のノードプールのオペレーションを中断することがまずもって必要でしたが、今回からはアップグレードをそのまま進行させておき、別途ノードプールを新規作成する、などの方法も採れるようになりました)。
そのため、ノードプールのアップグレード中のトラブル対応については想定しておくべきシナリオがかなり簡略化されたように思います。
しかし、依然としてコントロールプレーンのアップグレード中は構成変更やキャンセルが一切行えないため、アップグレード中にトラブルが起きた場合の対応を考えておく必要があることは意識しておきましょう(例えば手動でノードプールのサイジングを行っている場合は、リクエストの急増などでノードを追加したいと思ってもコントロールプレーンのアップグレード中であればその完了を待つまでノードを追加することはできません)。
まとめ
Google Cloud Next '23 で登場した GKE のアップデートの中から、「ノードプールの並行アップグレード」について、実機検証を交えてご紹介しました。
多数のノードプールを抱えているクラスタではアップグレードの総所要時間の短縮や、トラブル発生時のロールバックの高速化などに役立ちそうです。
地味ながら、日々 GKE の運用と格闘している人たちにとっては大きなアップデートになったのではないでしょうか。
GKE Security Posture でクラスタとワークロードのセキュリティを監査・強化する
GKE 関連のセキュリティ強化に役立つ、GKE Security Posture ダッシュボード(以降、Security Posture)という機能が新たに GA しました。
この記事の執筆時点ではまだ GKE のリリースノートには載っていません。
ただし、Google Cloud ブログの英語版には GKE Security Posture ダッシュボードが GA したことを紹介している記事が出ていました。
機能概要
Security Posture では、GKE クラスタとクラスタ上に展開されたワークロード構成を自動的にスキャンし、主に以下の観点で結果をダッシュボードに可視化してくれます。
- 重大度別に分類したセキュリティの懸念事項
- ワークロードに含まれるコンテナイメージの脆弱性スキャンの結果
- 運用しているクラスタに関連したセキュリティパッチや Issue の公開情報
- Security Posture の設定(監査対象となっているクラスタやワークロードの確認)
- セキュリティを強化するためのナレッジ(動画)へのリンク
Security Posture は Autopilot クラスタと Standard クラスタ のどちらにも対応し、無料で利用することができます1。
既存のクラスタに対して有効化することもできますが、無料の機能ということもありバージョン 1.27 以降の GKE クラスタでは今後自動的に有効化されるようです。
また、ダッシュボードとしては GA しているものの、一部の機能(ワークロードの構成スキャン)はプレビュー、というステータスとなっています。
なお、ワークロードを直接監視してコンテナランタイムへの攻撃を検出するといったことはできません。
そうしたソリューションが必要な場合は、Sysdig (Falco) , Prisma Cloud, Google Cloud であれば Security Command Center の Container Threat Detection などが選択肢になるでしょう。
(これらの機能を利用するには別途料金が必要です)
イメージレジストリに対する脆弱性スキャンや、CI パイプライン中でオンデマンドに行う脆弱性スキャンはできません。
ワークロードを展開する前にイメージスキャンを行いたい場合は、Google Cloud であれば Container Analysis がその機能を提供しています。
(こちらも別途料金が必要です)
実機の様子
実際に手元の環境で Security Posture を有効化し、クラスタとワークロードの監査を行ってみました。
Security Posture の利用を開始する(Container Security API を有効化し、スキャン対象のクラスタを選択する)手順は 公式ドキュメント を参照ください。
サンプルのクラスタに適当な Nginx のワークロードを展開したところ、Security Posture のダッシュボードは以下のような表示になりました。
今回はひとつのクラスタのみを Security Posture の監査対象に設定しましたが、複数のクラスタを選択すれば、監査対象となっている全てのクラスタのスキャン結果がまとめてダッシュボードに表示されます。

「懸念事項」のタブをクリックして表示を切り替えると、セキュリティの懸念事項を重大度、分類、ロケーション、クラスタで絞り込めるようになっていました。

Kubernetes Namespace やワークロードでも絞り込めるようになっているのが良いですね。

ここからは、検出されたセキュリティの懸念事項のカテゴリ別(脆弱性、セキュリティに関する公開情報、構成)に、どのような情報が参照できるのかをみていきましょう。
まずは脆弱性のカテゴリから、bind9/1:9.18.12-1 の CVE-2023-2911(debian) という項目を選択しました。
実行中のワークロード(Nginx)に含まれる CVE-2023-2911 の脆弱性についての説明と、推奨される対応、修正されたバージョンなどが確認できます。

次に、セキュリティに関する公開情報のカテゴリから、GCP-2023-008 の項目を選択しました。
こちらは GKE の Security Bulletins に掲載されているセキュリティ Issue の番号と一致したものとなっており、GKE に関連する CVE や、GKE としての対応状況(どのバージョンにアップグレードすれば該当のセキュリティ Issue が解消されるか)などを確認できるようになっています。

このカテゴリに関しては、個々のワークロードというよりも GKE のコントロールプレーンやノードプールに属するノードが影響先となります。
そのため、「影響を受けるリソース」のタブをクリックして表示を切り替えると、Issue の影響を受ける可能性のあるクラスタやノードプールが表示されるようになっていました。

最後に、構成のカテゴリから、root として実行可能な Pod コンテナ の項目を見てみましょう。
こちらはワークロードの定義情報をスキャンし、よりセキュアなマニフェストを書くための推奨事項などが提示されるようになっています。
今回は意図的に Pod の SecurityContext に runAsNonRoot: true を設定せずにデプロイしたため、スキャン結果として root ユーザでの実行が可能である(ゆえにコンテナブレイクアウトのリスクが高くなる)ことが検出されています。

所感
こうしたセキュリティの監査機能は、GKE クラスタやノードの OS といったインフラストラクチャに対する懸念事項と、コンテナイメージの脆弱性スキャンの結果、マニフェストの改善点など、それぞれの観点で別々のダッシュボードや機能が提供されていることが比較的多かったかなと思います。
今回登場した Security Posture では、GKE とそこで稼働するワークロードのセキュリティの懸念事項をまとめて確認でき、必要に応じて情報を絞り込んでいける点が視覚的にわかりやすく作られている印象を受けました。
従来、COS の脆弱性などの、GKE クラスタに関するセキュリティ Issue やパッチの配信状況は Security Bulletins をチェックして各自のクラスタにとっての該当有無を判断する必要がありました。
一方、Security Posture では、利用しているクラスタの構成に応じて該当するセキュリティ Issue だけを表示してくれるため、この機能が登場したことでそうしたパッチの配信状況を確認しやすくなりますね。
また、稼働中のワークロードのコンテナイメージに含まれる脆弱性のスキャンもプラスアルファのセキュリティ対策として有効に使えそうです。
イメージの脆弱性スキャンは、レジストリやオンデマンド実行を対象に導入を始めるケースが多いかとは思いますが、ビルドした後に発見された脆弱性や、レジストリに未登録のコンテナイメージが利用されてしまった場合など、それだけではカバーしきれないセキュリティリスクというものも考えられます。
実行中のワークロードに対しても定期的にスキャンが行われることで、より脆弱性の影響を評価しやすくなるのではないでしょうか。
まとめ
GKE Security Posture ダッシュボードが GA になりました。
クラスタとワークロードの構成をスキャンすることで、セキュリティ上の懸念事項を一元的に確認できる機能となっています。
最新以降のバージョンではデフォルトで有効化されることから、今後の GKE クラスタのセキュリティ管理におけるスタンダードとして活躍が期待できそうです。
GKE で FQDN による Network Policy を定義する
GKE において、FQDN に基づく Network Policy が定義できるようになりました。
この記事では、FQDN Network Policy の概要と、実際に使ってみた様子をご紹介したいと思います。
リリースノートはこちら。
FQDN Network Policy 登場の背景と概要
GKE では現在 2 つのネットワーキングの実装(Calico と Dataplane V2 (cillium))1 が提供されており、iptable に基づく制御か、eBPF に基づく制御か、といった違いはあるものの、いずれも Kubernetes Network Policy を利用することができました。
Kubernetes Network Policy では、クラスタ内における Pod 間通信であれば、namespaceSelector や podSelector といったラベルで送信元や宛先のワークロードを選択することができます。
一方、送信元や宛先がクラスタ外となる場合には、ipBlocks で対象の IP アドレスレンジを指定する以外に Network Policy で通信を制御する方法はありませんでした。
今回新たに登場した FQDN Network Policy では、Pod から送信する通信の宛先がクラスタ外となる場合に、FQDN で宛先を指定することができるようになりました。
これにより、宛先の IP アドレスが変動するような場合でも、FQDN に基づいて名前解決ができれば Network Policy を変更することなく下り通信(クラスタ内からクラスタ外への通信)を制御することができます。
許可する FQDN の指定には、正規表現を用いたパターンマッチングを利用することも可能となっています。
現時点では許可設定のみ行うことができ、明示的な拒否設定はできません。
Kubernetes Network Policy と同様、ポリシーを適用すると、対象のワークロードは許可された宛先以外には通信できなくなります(未許可のドメインに対しても dig や nslookup による名前解決は行うことができますが、実際には解決された IP アドレス宛てに通信することができなくなります)。
ちなみに、この記事の執筆時点ではプレビューでの提供となっていますが、今後 GA した際には有料の機能となるようです。
FQDN network policy is a paid feature, but payment will not be required at this time until FQDN network policy becomes a generally available offering.
利用にあたり、現時点では以下のような制約があります。
(なお、制約の正確なリストは 公式ドキュメント を参照ください)
- 1.26.4-gke.500+ もしくは 1.27.1-gke.400+ の GKE が必要(Standard でも Autopilot でも利用可能)
- 対象の GKE クラスタで Dataplane V2 が有効化されていること
- GKE のクラスタ内 DNS の機能である kube-dns または Cloud DNS が使われていること(自己管理の DNS サーバはサポート対象外)
- Anthos Service Mesh を有効化している環境では利用できない
- FQDNNetworkPolicy リソースのネットワーク ポリシー ロギングはサポートされていない
実機検証
今回は 1.26.4-gke.500 の GKE Standard のクラスタを用意しました。
FQDN Network Policy の有効化は、クラスタの作成時でも、作成済みのクラスタに後からでも行えます。
今回は FQDN Network Policy を有効化せずに既に作成していたクラスタに対して、後から有効化してみることにします。
$ gcloud container clusters describe sample-cluster
currentMasterVersion: 1.26.4-gke.500
currentNodeVersion: 1.26.4-gke.500
name: sample-cluster
networkConfig:
dnsConfig:
clusterDns: CLOUD_DNS
clusterDnsScope: CLUSTER_SCOPE
enableFqdnNetworkPolicy: true
...
$ gcloud beta container clusters update sample-cluster --enable-fqdn-network-policy
Updating sample-cluster ...done.
Updated [https://container.googleapis.com/v1beta1/projects/**********/zones/us-central1-c/clusters/sample-cluster].
To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/...
$ kubectl rollout restart ds -n kube-system anetd
daemonset.apps/anetd restarted
上記の手順によってクラスタに FQDNNetworkPolicy というリソースを扱うための CRD が展開されます。
展開された CRD は kubectl get/describe crd コマンドなどで確認することができます。
$ kubectl describe crd fqdnnetworkpolicies.networking.gke.io
Name: fqdnnetworkpolicies.networking.gke.io
Namespace:
Labels: addonmanager.kubernetes.io/mode=Reconcile
Annotations: components.gke.io/layer: addon
controller-gen.kubebuilder.io/version: v0.6.2
API Version: apiextensions.k8s.io/v1
Kind: CustomResourceDefinition
Spec:
Conversion:
Strategy: None
Group: networking.gke.io
Names:
Kind: FQDNNetworkPolicy
List Kind: FQDNNetworkPolicyList
Plural: fqdnnetworkpolicies
Short Names:
fqdnnp
Singular: fqdnnetworkpolicy
Scope: Namespaced
...
kube-system に展開されている anetd (Dataplane V2 を構成するサービスのひとつ)を再起動する必要がありますので注意しましょう。
(私はこの手順を見逃して少々の時間を溶かしました)
準備ができたので FQDNNetworkPolicy を定義して適用してみましょう。
動作確認のために Nginx のサンプルアプリも展開します。
$ cat fqdnnetpol.yaml
apiVersion: networking.gke.io/v1alpha1
kind: FQDNNetworkPolicy
metadata:
name: allow-out-fqdnnp
spec:
podSelector:
matchLabels:
app: curl-client
egress:
- matches:
- pattern: "*.yourdomain.com"
- name: "www.google.com"
ports:
- protocol: "TCP"
port: 443
$ kubectl apply -f fqdnnetpol.yaml
fqdnnetworkpolicy.networking.gke.io/allow-out-fqdnnp created
$ kubectl run nginx --image nginx
pod/nginx created
$ kubectl get pod nginx --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 3d23h app=curl-client
今回はコンテナに kubectl exec コマンドでログインして動作を確認します。
まずは FQDNNetworkPolicy で許可したドメインと、そうでないドメインへそれぞれ nslookup および curl コマンドを実行してみましょう。
$ kubectl exec nginx -it -- bash root@nginx:/# nslookup www.google.com Server: 169.254.169.254 Address: 169.254.169.254#53 Non-authoritative answer: Name: www.google.com Address: 142.250.1.99 Name: www.google.com Address: 142.250.1.104 Name: www.google.com Address: 142.250.1.105 Name: www.google.com Address: 142.250.1.106 Name: www.google.com Address: 142.250.1.147 Name: www.google.com Address: 142.250.1.103 Name: www.google.com Address: 2607:f8b0:4001:c0f::67 Name: www.google.com Address: 2607:f8b0:4001:c0f::69 Name: www.google.com Address: 2607:f8b0:4001:c0f::93 Name: www.google.com Address: 2607:f8b0:4001:c0f::68 root@nginx:/# curl -I -m 3 https://www.google.com HTTP/2 200 ... root@nginx:/# nslookup www.cloudflare.com Server: 169.254.169.254 Address: 169.254.169.254#53 Non-authoritative answer: Name: www.cloudflare.com Address: 104.16.123.96 Name: www.cloudflare.com Address: 104.16.124.96 Name: www.cloudflare.com Address: 2606:4700::6810:7c60 Name: www.cloudflare.com Address: 2606:4700::6810:7b60 root@nginx:/# curl -I -m 3 https://www.cloudflare.com curl: (28) Connection timed out after 3000 milliseconds
期待どおり、許可されたドメインにのみアクセスできる状態となっています。
許可されていないドメインへの通信はエラー返却ではなくドロップになるため、アプリケーションの視点ではリトライやタイムアウトの上限に達するまで通信の失敗に気付けない点に注意が必要です。
ちなみに、適用したポリシーはプロトコルを指定した許可設定のため、http (port 80) でアクセスしようとすると、許可されたドメインであっても通信は失敗(ドロップ)します。
root@nginx:/# curl -I -m 3 http://www.google.com curl: (28) Connection timed out after 3000 milliseconds
なお、プロトコルは TCP, UDP, ALL の 3 つから選択でき、無指定の場合は ALL になります。
ポリシーの ports フィールド以下を省略して、プロトコルやポート番号を問わない設定とすれば、http でも対象のドメインにアクセスできるようになります。
$ kubectl explain FQDNNetworkPolicy.spec.egress.ports.protocol
GROUP: networking.gke.io
KIND: FQDNNetworkPolicy
VERSION: v1alpha1
FIELD: protocol <string>
DESCRIPTION:
Protocol is the L4 protocol. Valid options are "TCP", "UDP", or "ALL". If
Protocol is missing or empty, it defaults to allowing all protocols.
$ cat fqdnnetpol.yaml
apiVersion: networking.gke.io/v1alpha1
kind: FQDNNetworkPolicy
metadata:
name: allow-out-fqdnnp
spec:
podSelector:
matchLabels:
app: curl-client
egress:
- matches:
- pattern: "*.yourdomain.com"
- name: "www.google.com"
$ kubectl apply -f fqdnnetpol.yaml
fqdnnetworkpolicy.networking.gke.io/allow-out-fqdnnp configured
$ kubectl exec nginx -it -- bash
root@nginx:/# curl -I -m 3 http://www.google.com
HTTP/1.1 200 OK
...
利用時の注意点
公式ドキュメントでも言及されていますが、FQDN Network Policy と Kubernetes Network Policy には上下関係がありません。
そのため、同じワークロードに対して両方のポリシーが定義されている場合は、どちらかひとつでも一致する許可設定があればその通信は許可(クラスタ外に送信)されます。
どちらか一方だけのポリシーを見ても許可設定の全量が把握できないため、利用する際は注意が必要です。
まとめ
GKE で FQDN に基づく Network Policy が利用できるようになりました。
クラスタ外の通信先の IP アドレスが動的に変動するなどの場合に活躍してくれそうな機能ですね。
※ 2023/6/29 追記 記事公開の直前に Autopilot でも利用可能となったとアナウンスがあったため、GKE Standard のみ利用可能としていた記載を更新しました
- 厳密には、Calico と Dataplane V2 の他に GKE のネイティブ CNI という実装もありますが、こちらは Network Policy を利用できないためここでは割愛しています↩
Konnectivity とは
今回は、Kubernetes のコントロールプレーンとノードの間の通信を支える Konnectivity サービスについてみていきます。
きっかけは、最近 GKE の release notes で見かけた以下のアナウンスでした。
For VPC peering-based private clusters running version 1.27 or later, traffic from kube-apiserver to nodes routes through the Konnectivity service. If your cluster was created before 2020-09-17, this traffic from does not route through Konnectivity unless you have rotated the control plane IP address after 2020-09-17.
以前から GKE の kube-system にも Konnectivity の名前をもつ Pod がおり、なんとなくコントロールプレーンとノード間の通信に関与しているんだろうくらいの認識だったのですが、これをきっかけに実際の通信がどのように変化するのか把握しておきたいと思い調べてみました。
Konnectivity サービスの概要
Konnectivity はコントロールプレーンからクラスタへの通信に TCP プロキシを提供するサービスです。
Kubernetes API Server (kube-apiserver) などのコントロールプレーンも包含して「クラスタ」という言葉が使われることもありますが、ここではコントロールプレーンを含まず、ノード, Pod, サービス などのワークロードが実行される環境を指しています。
Konnectivity サービスは、サーバとエージェントの 2 つの役割から構成されるもので、コントロールプレーン側に Konnectivity サーバを、クラスタ側に Konnectivity エージェントを配置します。
Konnectivity サービスが有効なクラスタでは、Kubernetes API Server などのコントロールプレーンのコンポーネントから、クラスタ宛ての通信は Konnectivity サーバと Konnectivity エージェントの間に作成されたネットワーク接続を経由することになります。
Konnectivity エージェントは必ずすべてのノードに配置されている必要はありません。
実際、GKE の実装では GKE ノードに配置される Konnectivity エージェントは Deployment (とレプリカ数を動的に調整するためのオートスケーラ)で管理されており、Konnectivity エージェントが配置されないノードができることもあります。
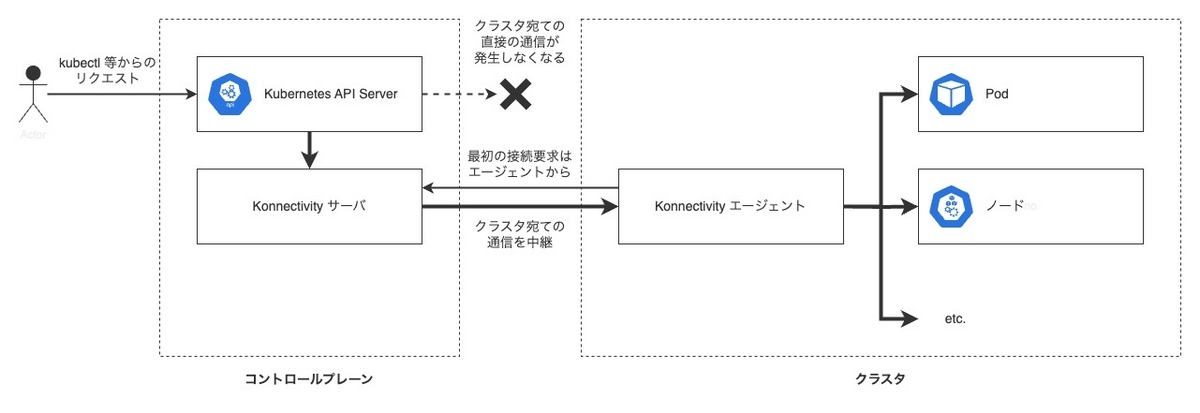
※ Konnectivity サーバには「クラスタ向けの TCP プロキシ」と「Kubernetes API Server からコントロールプレーン内の他のコンポーネント向けの TCP プロキシ」のふたつの機能があるようですが、ここでは説明の簡単のため前者のみを描いています
Kubernetes の公式ドキュメントでは、こちらのページ で Konnectivity サービスについて説明されています。
何が嬉しいのか
Konnectivity サービスを利用することで、Kubernetes API Server がクラスタ内部(ノード, Pod, サービス, etc.)に直接接続しなくなるため、クラスタ内部で行われるネットワーキングと分離してトラフィックを管理することができるようになります。
これらを分離できることで、コントロールプレーンとクラスタネットワークの IP アドレスが重複することを許容できるようになったり、セキュリティの強化につながります。
Konnectivity サービスの登場以前、コントロールプレーンからクラスタへの通信(例えば Kubernetes API Server からノードへの通信)には、プレーン HTTP ないし SSH が利用されてきました。
しかし、プレーン HTTP ではセキュリティ上の懸念があり、SSH によるトンネリングはクラウドベンダによっては提供されていない場合もありました(現在では SSH によるトンネリングは非推奨となっています)。
一方、Konnectivity サービスは(リファレンスの実装であれば)エージェントを Kubernetes の Pod として実行するため、ノードの実装を問わず共通的な仕組みでコントロールプレーンからノード宛ての通信を分離することができます。
また、GKE のようにクラウドベンダが Kubernetes のコントロールプレーンをサービスとして提供する場合、コントロールプレーンとノードは異なるネットワークで実行されることになります。
そうした環境では、過去、/api/v1/namespaces/$NS/pods/$POD/status への書き込み権限を持つ攻撃者が Pod の IP アドレスを変更することで 、Kubernetes API Server が実行されているネットワーク内のサーバに対して HTTP リクエストを送信できることが知られていました ※ 。
Kubernetes の管理下であれば、RBAC などで適切に権限管理することでこれを制限することができますが、ノードに直接アクセスできる場合においては権限制御で防ぐことができません(攻撃者が kubelet になりすます可能性があるため)。
Konnectivity サービスが TCP プロキシとして機能し、コントロールプレーンからノードへの直接アクセスが行われないようにすることで、こうしたセキュリティ上の懸念を回避するという目的もあるようです。
※ https://groups.google.com/g/kubernetes-security-announce/c/tyd-MVR-tY4/m/tyREP9-qAwAJ
独立したサービスであるメリット
Kubernetes API Server に機能を追加するのではなく、コントロールプレーン内の他のコンポーネントと独立したサービスとして設計されていることには理由があります。
コントロールプレーンからクラスタへの接続管理に関する責務を Konnectivity サービスに集約することで、コントロールプレーンからクラスタへの通信を監査するための独自のプロキシサーバを構成できるようになったり、コントロールプレーンとクラスタ間の接続を Kubernetes API Server が管理する必要がなくなったりするといったメリットがあります。
詳しくは、Konnectivity サービスの提案時に作成された KEP (Kubernetes Enhancement Proposal) を参照ください。
なお、Kubernetes API Server と Konnectivity サーバの間の通信には、HTTP Connect または gRPC が利用できるようです。
EgressSelectorConfiguration というリソースでプロトコルが指定できるようになっています。
詳しいセットアップ方法は下記の Kubernetes 公式ドキュメントに掲載されています:
まとめ
Kubernetes のコントロールプレーンとノードの間の通信を管理する Konnectivity サービスについて調べました。
Konnectivity サービスはコントロールプレーンからクラスタへの通信に TCP プロキシを提供します。
これにより、GKE のようにコントロールプレーンとノードの実行されるネットワークが異なる場合でも、コントロールプレーンからノードへの直接アクセスが行われなくなることで(Firewall などを併用して)セキュリティを高めることができるようになります。
GKE では、1.27 以降のプライベートクラスタ(限定公開クラスタ)で Konnectivity サービスが使われるようになるとのアナウンスがありました。
1.27 を利用開始する際には、実機での検証もしてみたいと思います。
なお、上記の説明は私の調査と理解に基づくもので、正確な情報については各種公式ドキュメントを参照ください。
Google Cloud のロードバランサでクライアント認証を行う
Google Cloud のロードバランサ (Cloud Load Balancing) でクライアント認証が行えるようになりました。
この記事では、ロードバランサにクライアント認証の機能をセットアップして動作を確認するまでの流れと、使ってみての気付きなどをご紹介します。
概要
今回リリースされた機能は、クライアントとサーバが TLS プロトコルを用いて互いに認証を行うことから、公式ドキュメントでは mTLS (mutual TLS, 相互 TLS) 機能と表現されています。
通常の HTTPS 通信ではクライアントがサーバやロードバランサを一方的に検証しますが、サーバ/ロードバランサによるクライアントの検証も併せて行うことで、認証済みの(証明書を配布した)クライアントだけをサービスにアクセスさせるよう制限することができます。
なお、現時点(2023年4月)ではプレビューの機能となっており、グローバル外部 HTTP(S) ロードバランサ、およびグローバル外部 HTTP(S) ロードバランサ(classic)で利用可能となっています。
リリースノートはこちら。
実機検証
ここからは、mTLS 機能を有効にしたグローバル外部 HTTP(S) 負荷分散をセットアップし、実際にクライアント認証に成功するまでの流れを見ていきます。
まずはクライアント認証を行うためのプライベート認証局(CA)や各種リソースを作成します。
今回は こちらの公式ドキュメント を参考に、Certificate Authority Service を利用してプライベート認証局を作成しました。
$ gcloud privateca pools create sample-ca-pool \ --location=us-central1 $ gcloud privateca roots create sample-ca-root \ --pool=sample-ca-pool \ --subject="CN=my-ca, O=Test LLC" \ --location=us-central1 $ gcloud privateca roots describe sample-ca-root \ --pool=sample-ca-pool \ --location=us-central1 \ --format='value(pemCaCertificates)' > root.cert $ export ROOT=$(cat root.cert | sed 's/^[ ]*//g' | tr '\n' $ | sed 's/\$/\\n/g')
プライベート認証局を使用して生成されたルート証明書が取得できたので、これを元に TrustConfig という Certificate Manager のリソースを作成し、インポートします。
TrustConfig では、クライアント証明書の検証時に使用するルート証明書や中間証明書を YAML 形式で定義します。
$ cat << EOF > trust_config.yaml
name: sample-trust-config
trustStores:
- trustAnchors:
- pemCertificate: "${ROOT?}"
EOF
$ gcloud beta certificate-manager trust-configs import sample-trust-config \
--source=trust_config.yaml
Request issued for: [sample-trust-config]
Waiting for operation [projects/*****************/locations/global/operations/operation-...] to complete...done.
createTime: '2023-04-24T13:26:58.877956234Z'
etag: *****************
name: projects/*****************/locations/global/trustConfigs/sample-trust-config
trustStores:
- trustAnchors:
- pemCertificate: |
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
updateTime: '2023-04-24T13:27:03.054424153Z'
次に、クライアント証明書の検証結果に応じたロードバランサの振る舞いを、ServerTLSPolicy というリソースで定義します。
ServerTLSPolicy の clientValidationMode というフィールドに対して、現時点では以下の 2 つのモードが提供されており、どちらのモードを選択するかによって検証結果に応じた振る舞いが決まります。
- ALLOW_INVALID_OR_MISSING_CLIENT_CERT
検証が失敗したり、クライアント証明書が無いリクエストであっても、すべてのリクエストがバックエンドに渡されます。どのような検証エラーがあったかは、バックエンドにカスタムヘッダで伝達することができます。
- REJECT_INVALID
クライアント証明書の検証に成功したリクエストだけがバックエンドに渡されます(検証が失敗したり、クライアント証明書が無いリクエストはすべて拒否されます)。
今回は、クライアント証明書の有無でレスポンスの違いやエラーメッセージを確認するため、REJECT_INVALID モードでポリシを作成します。
$ cat << EOF > server_tls_policy.yaml
name: sample-server-tls-policy
mtlsPolicy:
clientValidationMode: REJECT_INVALID
clientValidationTrustConfig: projects/*************/locations/global/trustConfigs/sample-trust-config
EOF
$ gcloud beta network-security server-tls-policies import sample-server-tls-policy \
--source=server_tls_policy.yaml \
--location=global
Request issued for: [sample-server-tls-policy]
Waiting for operation [projects/*****************/locations/global/operations/operation-...] to complete...done.
createTime: '2023-04-24T14:23:22.526368220Z'
mtlsPolicy:
clientValidationMode: REJECT_INVALID
clientValidationTrustConfig: projects/*****************/locations/global/trustConfigs/sample-trust-config
name: projects/*****************/locations/global/serverTlsPolicies/sample-server-tls-policy
updateTime: '2023-04-24T14:23:26.738032825Z'
ServerTLSPolicy の用意ができたら、ロードバランサに mTLS を設定します。
今回は、対象として Cloud Run のサンプルアプリをバックエンドに設定したグローバル外部 HTTP(S) ロードバランサを用意しました。
$ gcloud compute forwarding-rules describe sample-https-forwarding-rule --global IPAddress: ***************** IPProtocol: TCP creationTimestamp: '2023-04-25T07:30:28.545-07:00' description: '' fingerprint: ***************** id: '*****************' kind: compute#forwardingRule labelFingerprint: ***************** loadBalancingScheme: EXTERNAL_MANAGED name: sample-https-forwarding-rule networkTier: PREMIUM portRange: 443-443 selfLink: https://www.googleapis.com/compute/v1/projects/*****************/global/forwardingRules/sample-https-forwarding-rule target: https://www.googleapis.com/compute/v1/projects/*****************/global/targetHttpsProxies/sample-target-https-proxy $ gcloud compute target-https-proxies describe sample-target-https-proxy --global creationTimestamp: '2023-04-25T07:29:55.982-07:00' fingerprint: ***************** id: '*****************' kind: compute#targetHttpsProxy name: sample-target-https-proxy selfLink: https://www.googleapis.com/compute/v1/projects/*****************/global/targetHttpsProxies/sample-target-https-proxy serverTlsPolicy: //networksecurity.googleapis.com/projects/*****************/locations/global/serverTlsPolicies/sample-server-tls-policy sslCertificates: - https://www.googleapis.com/compute/v1/projects/*****************/global/sslCertificates/sample-ssl-cert urlMap: https://www.googleapis.com/compute/v1/projects/*****************/global/urlMaps/sample-url-map $ gcloud compute url-maps describe sample-url-map creationTimestamp: '2023-04-24T20:36:36.845-07:00' defaultService: https://www.googleapis.com/compute/v1/projects/*****************/global/backendServices/sample-backend-service fingerprint: ***************** id: '*****************' kind: compute#urlMap name: sample-url-map selfLink: https://www.googleapis.com/compute/v1/projects/*****************/global/urlMaps/sample-url-map $ gcloud compute backend-services describe sample-backend-service --global affinityCookieTtlSec: 0 backends: - balancingMode: UTILIZATION capacityScaler: 1.0 group: https://www.googleapis.com/compute/v1/projects/*****************/regions/us-central1/networkEndpointGroups/sample-app-neg connectionDraining: drainingTimeoutSec: 0 creationTimestamp: '2023-04-24T20:35:36.863-07:00' description: '' enableCDN: false fingerprint: ***************** id: '*****************' kind: compute#backendService loadBalancingScheme: EXTERNAL_MANAGED name: sample-backend-service port: 80 portName: http protocol: HTTP selfLink: https://www.googleapis.com/compute/v1/projects/*****************/global/backendServices/sample-backend-service sessionAffinity: NONE timeoutSec: 30 $ gcloud compute network-endpoint-groups describe sample-app-neg --region=us-central1 cloudRun: service: hello creationTimestamp: '2023-04-24T20:35:10.266-07:00' id: '*****************' kind: compute#networkEndpointGroup name: sample-app-neg networkEndpointType: SERVERLESS region: https://www.googleapis.com/compute/v1/projects/*****************/regions/us-central1 selfLink: https://www.googleapis.com/compute/v1/projects/*****************/regions/us-central1/networkEndpointGroups/sample-app-neg size: 0
こちらの公式ドキュメント を参考に、上記のロードバランサに対してmTLS を設定します。
$ gcloud compute target-https-proxies export sample-target-https-proxy \ --global \ --destination=xlb-mtls-target-proxy.yaml $ echo "serverTlsPolicy: //networksecurity.googleapis.com/projects/PROJECT_ID/locations/global/serverTlsPolicies/sample-server-tls-policy" >> xlb-mtls-target-proxy.yaml $ cat xlb-mtls-target-proxy.yaml creationTimestamp: '2023-04-25T04:40:45.875-07:00' kind: compute#targetHttpsProxy name: sample-target-https-proxy selfLink: https://www.googleapis.com/compute/v1/projects/*****************/global/targetHttpsProxies/sample-target-https-proxy sslCertificates: - https://www.googleapis.com/compute/v1/projects/*****************/global/sslCertificates/sample-ssl-cert urlMap: https://www.googleapis.com/compute/v1/projects/*****************/global/urlMaps/sample-url-map serverTlsPolicy: //networksecurity.googleapis.com/projects/*****************/locations/global/serverTlsPolicies/sample-server-tls-policy $ gcloud compute target-https-proxies import sample-target-https-proxy \ --global \ --source=xlb-mtls-target-proxy.yaml Target Https Proxy [sample-target-https-proxy] will be overwritten. Do you want to continue (Y/n)? Y Updating TargetHttpsProxy...done.
クライアント証明書の検証に失敗した場合にログが出力されるよう、バックエンドサービスを設定します。
今回は利用しませんが、クライアント証明書の検証結果がエラーとなった場合に取得できる情報もカスタムヘッダに設定しておきました。
$ gcloud compute backend-services update sample-backend-service \
--global \
--enable-logging \
--logging-sample-rate=1 \
--custom-request-header='X-Client-Cert-Present:{client_cert_present}' \
--custom-request-header='X-Client-Cert-Chain-Verified:{client_cert_chain_verified}' \
--custom-request-header='X-Client-Cert-Error:{client_cert_error}' \
--custom-request-header='X-Client-Cert-Hash:{client_cert_sha256_fingerprint}' \
--custom-request-header='X-Client-Cert-Serial-Number:{client_cert_serial_number}' \
--custom-request-header='X-Client-Cert-SPIFFE:{client_cert_spiffe_id}' \
--custom-request-header='X-Client-Cert-URI-SANs:{client_cert_uri_sans}' \
--custom-request-header='X-Client-Cert-DNSName-SANs:{client_cert_dnsname_sans}' \
--custom-request-header='X-Client-Cert-Valid-Not-Before:{client_cert_valid_not_before}' \
--custom-request-header='X-Client-Cert-Valid-Not-After:{client_cert_valid_not_after}'
それでは準備ができたので実際にリクエストしてみましょう。
まずはクライアント証明書を持たないリクエストを wget で発行してみます。
(サーバ証明書は自己署名の適当なものを設定したため、no-check-certificate オプションで証明書検証をスキップしています)
$ wget --no-check-certificate -t 1 https://*****************:443 --2023-04-26 14:35:33-- https://*****************/ Connecting to *****************:443... connected. WARNING: Could not save SSL session data for socket 3 WARNING: The certificate of ‘*****************’ is not trusted. WARNING: The certificate of ‘*****************’ doesn't have a known issuer. The certificate's owner does not match hostname ‘*****************’ Failed writing HTTP request: The specified session has been invalidated for some reason.. Giving up.
リクエストに失敗しました。
wget のエラーメッセージだけでは失敗の理由がわからないため、Cloud Logging に出力されているロードバランサのログを確認してみます。

エントリの statusDetails が "client_cert_not_provided" となっており、クライアント証明書が提示されなかったためにリクエストが拒否されたことを確認できました。
今度は Certificate Authority Service のプライベート認証局で署名されたクライアント証明書を持たせて同様のリクエストを発行してみます。
$ wget --certificate client.crt --private-key client.key --no-check-certificate -t 1 https://*****************:443 --2023-04-26 14:47:07-- https://*****************/ Connecting to *****************:443... connected. WARNING: The certificate of ‘*****************’ is not trusted. WARNING: The certificate of ‘*****************’ doesn't have a known issuer. The certificate's owner does not match hostname ‘*****************’ HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Saving to: ‘index.html.3’ index.html.3 [ <=> ] 4.71K --.-KB/s in 0s 2023-04-26 14:47:08 (53.3 MB/s) - ‘index.html.3’ saved [4818]
リクエストが成功しました。
これで、クライアント証明書を持つクライアントだけを許可するロードバランサの mTLS 設定を確認できました。
検証の所感
前述の検証を通じて得た気付きをいくつかご紹介します。
clientValidationMode の変更
ServerTLSPolicy の clientValidationMode ではクライアント証明書の検証結果をどう処理するかを定義していました。
想定される利用シーンのひとつとして、開発過程では 'ALLOW_INVALID_OR_MISSING_CLIENT_CERT' で検証の成否に関わらずリクエストをバックエンドに渡しておき、本番の運用では 'REJECT_INVALID' でクライアント証明書を必須とする、といった場合もあるのではないかと思います。
一方、公式ドキュメントにも注記があるとおり、ServerTLSPolicy は一度リソースを作成すると上書きできない仕様となっています。
そのため、「同じトラストストアを利用するが異なるモードを使用したい」という場合は ServerTLSPolicy リソースを新たに作成する必要があることに注意しておきましょう。
なお、ポリシを適用する Target HTTP Proxy は import メソッドで更新が可能となっているため、clientValidationMode を変更する過程でロードバランサ自体を再作成する必要はありません。
クライアント証明書の失効
以下の公式ドキュメントの記載によると、現在のところロードバランサではクライアント証明書が無効化されているか否かの確認(revocation check)を行わないようです。
使い方によりますが、発行済のクライアント証明書を(有効期限内であっても)漏えい等の理由で無効化しなければならなくなるケースは十分に想定されるため、今後のアップデートに期待したいところです。
自己署名証明書の使用
これも同じく公式ドキュメントの制限事項に記載されていますが、自己署名クライアント証明書は、常にロードバランサによって無効とみなされます。
そのため、調査目的などで利用する際には注意が必要です。
まとめ
Google Cloud のロードバランサでクライアント認証が行えるようになりました。
このアップデートによって認証用サーバを別途構築する必要なくクライアント認証が行えるようになるため、該当するワークロードでは構成をシンプルにできるだけでなく、Cloud Armor の機能をフルに使ってワークロードを保護することもできるようになりました※。
※ バックエンドでクライアント認証を行う場合は外部 TCP プロキシ ロードバランサなどの L4 ロードバランサを用いる必要があるため、Cloud Armor の Security Policy も L4 で利用可能な機能に限定されていました